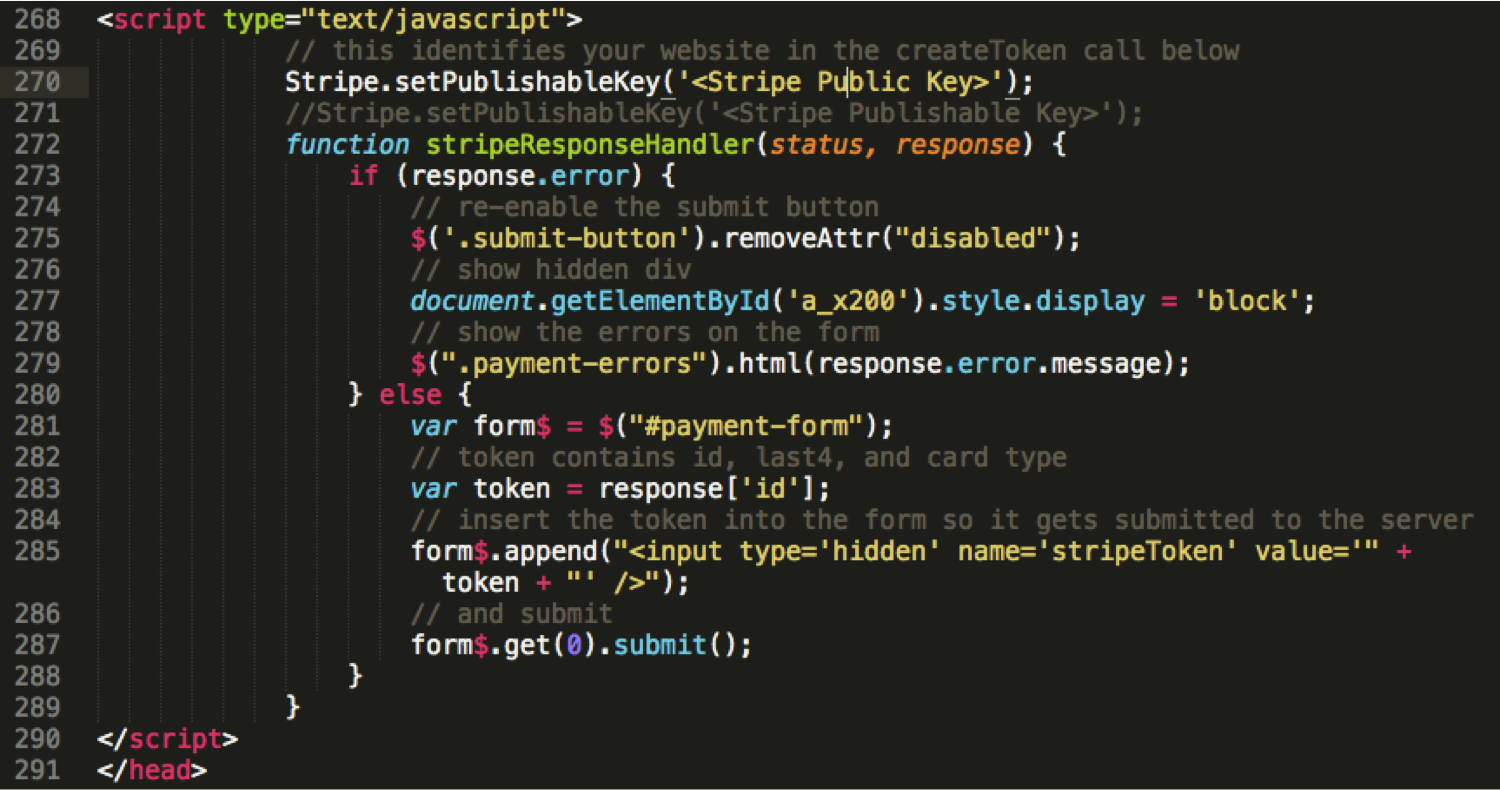
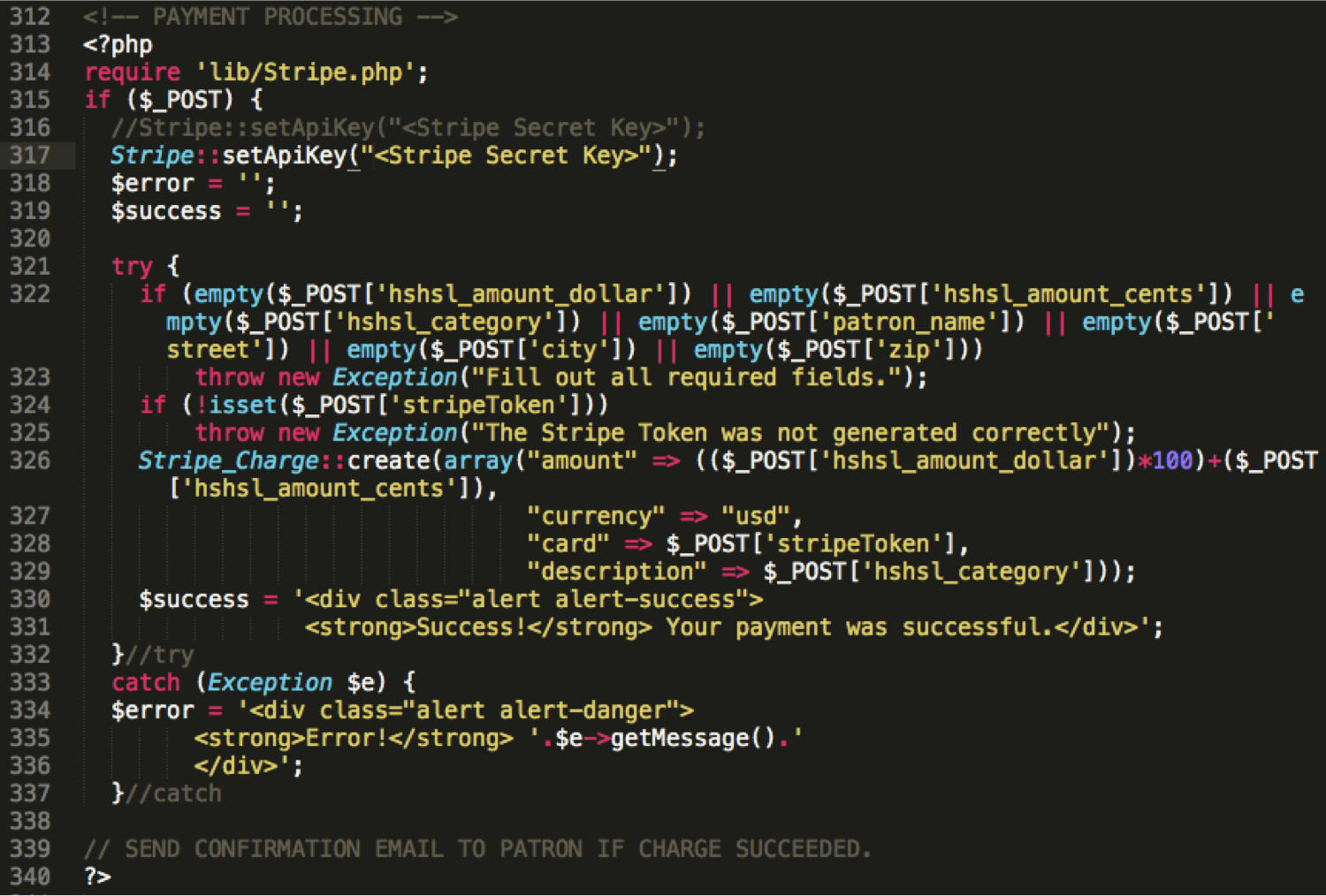
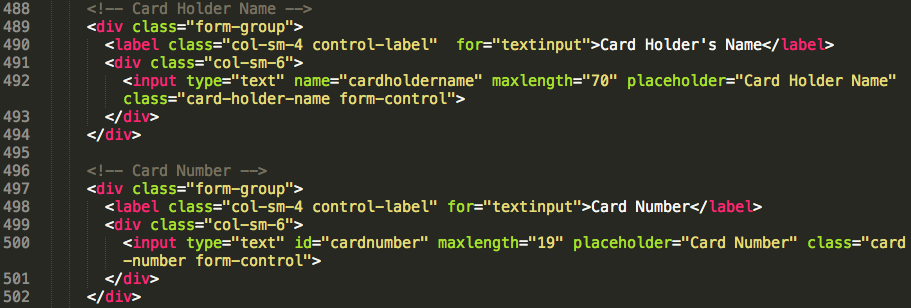
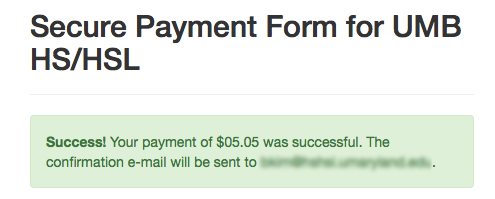
Below is my closing keynote, “Libraries Meet the Second Machine Age” given for the 2015 Library Technology Conference on March 19, 2015 at St. Paul, MN. I want to send big thanks to the conference steering committee who invited me and those who watched and shared my keynote either on-site or online and their thoughts and ideas with me. The topic was a bit unusual for a library conference. So I am particularly grateful for the opportunity I had to talk about this kind of topic with many others. (And imagine the surprise when it was actually well received.) For those interested, the video recording of the keynote is at http://www.ustream.tv/recorded/60105499. The slides are available at http://www.slideshare.net/bohyunkim/libraries-meet-the-second-machine-age.
*Â Â Â Â Â Â Â Â Â Â Â Â Â Â Â Â Â *Â Â Â Â Â Â Â Â Â Â Â Â Â Â Â Â Â Â Â *
Hi everyone, thank you for having me today. I am very excited to be here at LTC with all of you, library technologists. We are passionate about applying technology, so that our library patrons can succeed in their education, their jobs, and their lives.
1. What is Technology to Us?
If you would indulge me for a minute, I would like to play this short video. This video shows Tomatan, a wearable robot that sits on your shoulder and feeds you nutritious tomatoes while you are running so that you can defeat fatigue. As you can see from this Japanese invention, technology is evolving in a way that we have not fully anticipated before. What is technology to us today? This article in Harvard Business Review talks about a study of how self-service kiosks at chain restaurants such as Taco Bell or McDonald’s change customer behavior. This study found that when people are ordering their food with these self-service kiosks or in-house apps, they tend to spend about 30% more on food than when they order with a human server.
2. Today’s Libraries as Technology Hubs
Libraries are really shaking off the traditional image as a quiet reading room with stacks of books. More and more media coverage of libraries today focuses on the innovative technology being introduced at libraries for library patrons to utilize and try it out.
Take Google Glass for example. I know it has been phased out by Google for a while now for various reasons. But when it was a coveted cutting-edge technology item, it was libraries that acquired these items and started lending them to library patrons, so that the public can try it out, feel what it is like to wear a pair of Google Glasses, and experience what is like to live in the future. MacPhaidin Library at Stonehill College is one of those libraries that lends Google Glass. Similarly, University of Michigan Library’s 3D Lab offers equipment and services for 3d printing, advanced visualization, rapid prototyping, 3d scanning, and motion capture. Chicago public library has the Maker Lab, where library patrons can learn how to design a 3D model and 3D-print the digital models they made at the library. Stacie Library at York University held a Hackfest.
People no longer come to libraries just to borrow books. They come to libraries to rent tools, try and learn new technologies, participate in a hackathon, practice and record a video presentation, hold online conference meetings, and group study in libraries’ many technology-enabled spaces such as these equipped with a large LCD screen that can mirror the small computer screen.
And we have taken up all of these new things while continuing the traditional library services, such as bibliographic instruction, reference, cataloging, circulation, serials management, and systems. Many of us also revamped our library websites, OPACs, and other patron-facing online systems, so that our patrons can have excellent user experience. Many of us try to provide uniform and consistent user experience between the library’s online and physical space. Due to our strong interests in improving library patrons’ user experience, UX has become a common term widely used among librarians nowadays. Considering these, it seems that libraries emerged as a sure winner of the digital revolution. We offer what the public wants the way they want as much as we can.
The mass media sure seem to have noticed it. This article in the Huffington Post, for example, calls libraries ‘hubs of technology.’ But is there something we are missing in this picture or something we can do better? Libraries advocate technology and innovation. But so do many other institutions. How are libraries different?
Today, I would like to talk about information and libraries in the second machine age. Two things may strike you odd. First, what is the second machine age? Second, why does it matter to information and libraries? I will explain what the second machine age is in a moment. But I want to also tell you that I bring up this concept of the second machine age because I think it provides an important context for the role that information and technology play in our library patrons’ daily lives.
3. The Second Machine Age and Innovation
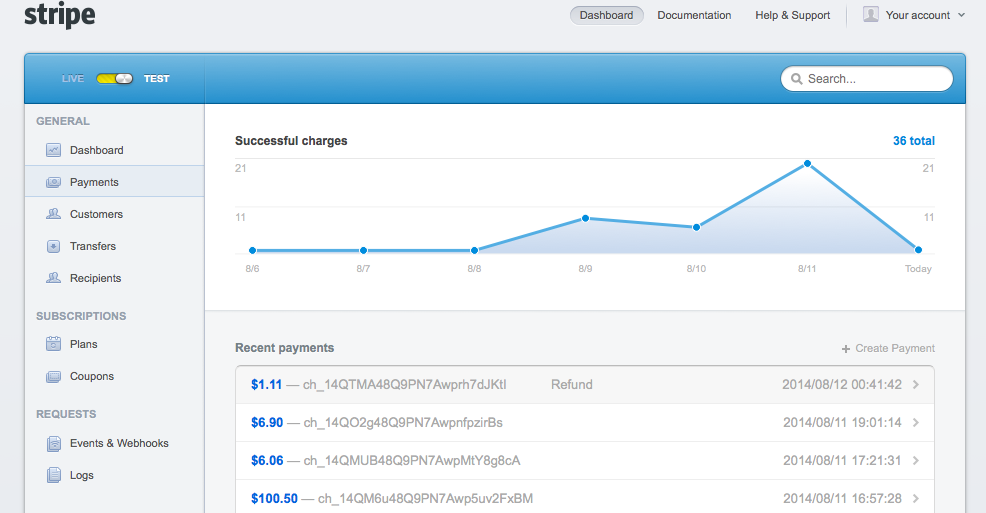
What made the second machine age possible was the digital revolution. The digital revolution refers to the shift from analog, mechanical, and electronic technology to digital technology. This began in the late 1950s with the adoption of digital computers and digital records. The World Wide Web started in 1991 and it has been thriving with the exponential growth of computing power as you can see from this graph.
This graph shows how drastically one dollar’s worth of computer power grew from 1980 to 2010. In 1980, with one dollar you could get the computing power for doing a billion computations 7-8 times per second. Only after 30 years in 2010, we reached the point where one dollar’s worth of computing gets us a billion computations over 100 million times over, during one second. From 7-8 times to one hundred million times, that is indeed an exponential growth.
One of the defining characteristics of the second machine age is smart machines and innovation. So let’s take a look at how innovation have changed our lives.
Some innovations are awesome. As many of you would recognize, this is the book bot at NCSU Libraries. No longer do patrons need to browse the stacks to locate the book they want. All they need is to put a request on a computer, and this book bot will retrieve the title for you.
Some innovations are liberating. In 2013, Michael Ebeling set up the first 3D printing lab in South Sudan to manufacture 3d printed prosthetic arms for local children who lost their arms and cannot afford commercial prosthetics. This area had a lot of people who lost their limbs due to the war and the mines left from the war. A 3D printed prosthetic arm costs only about $100 to make. But the cost of a commercial one ranges from $3000 to $30000. The locals learned how to 3d print the parts and assemble them into a prosthetic arm. So this will continue to benefit the people in that area.
Some innovations can change the research practice at an academic field. Since its founding in 2005, Mechanical Turk, a crowd-sourcing task system from Amazon, has become an increasingly popular way for university researchers to recruit subjects for online experiments and surveys. It’s cheap, easy to use, has about 500,000 workers. But as these Turkers complete and participate in a dozen or more surveys and experiments everyday for years, they have become professional surveyees and experimentees. Consequently, the responses to research surveys and experiments conducted at the Mechanical Turk have begun to show skewed results.
Some innovations can be simply harmful. As most of you know, Lenovo, the world’s largest PC maker was caught having the spyware that is a a huge security risk for users installed on its OS to increase a little bit of their revenue from selling out users’ web-browsing patterns.
Some innovations can harbinger a huge change from what we currently consider natural. An example of this is self-driving cars to be programmed and manufactured by technology companies such as Apple and Google, probably in the near future. What would happen to the taxi-industry or the car insurance industry if these self-driving cars become reality?
Some innovations can make us uncomfortable. More and more stores now have self-checkout machines. You have to ring up your own purchases, pay, and bag them yourself. These businesses cut their costs and maximize their profit by transferring the service labor that they used to provide, now to customers. The same has been happening with banks. There are far fewer bank branches now than several years ago and even those that stay open have a drastically smaller number of tellers because banks replaced them with ATMs.
Needless to say, this kind of technology innovation that results in the mass-scale automation has a huge impact on the economy. And we have been living with that impact for quite a while now.
4. What Is the Second Machine Age?
Economists Erik Brynjolfsson and Andrew McAfee at MIT observed the seemingly contradictory phenomenon in the current economy that productivity increases while employment stagnates or decreases. Traditionally, the growing productivity have meant more jobs. For that reason, we often equate economic growth with more employment opportunities. For example, in the first machine age, productivity, employment, and median income all rose in tandem. But in the second machine age, the growth in productivity has been decoupled from jobs and income. As this graph shows, productivity continues to go up as machines replace the human labor, bringing in more efficiency. But this now happens with less employment and wage stagnation instead of more employment opportunities and higher wages.
This is what economists call “the second machine ageâ€. And what is driving this new unwelcome trend is the rise of smart machines and their substitution for human labor.
Another economist Tyler Cowen at George Mason University also observed this phenomenon. He predicts that in the future, we will be living in the world where there are only two groups exist, highly-skilled and well-paid elites and the rest. He sees employment and wage polarization in the future due to the displacement effect of computerization. His book title “Average is over†summarizes this view. In this view, store clerks and bank tellers who lost their jobs due to the automated self-check out machines and ATMs were the first signs of this displacement effect of computerization.
So the simple and repetitive manual labor that can be easily automated by machines and even perform better than humans are going away. But the jobs that complement or improve the performance of machines are in high demand. Data scientist is one of such jobs. The digital revolution has enabled us to amass an astronomical amount of data. But in order to make sense of it and find usable patterns there, humans are still needed. Forbes called data scientist ‘the hottest jobs in IT.’ Harvard Business Review calls data scientist ‘the sexiest job of the 21st century.’
If you are familiar with chess, you will know that today’s world champions of chess are not chess geniuses but teams of computers and individuals who are good at utilizing these computers to determine the best move at a given point in a chess match. These are called Centaur teams and they are better chess players than humans alone or or machines alone.
The optimal interplay between humans and machines has become the new drive of today’s economic growth. Business and industry call for more highly skilled workforce who can work well with smart machines, while eliminating jobs that can be fully automated by machines. This thins out the middle class, diminishes the upward mobility, and increases the overall economic inequality.
A French economist, Thomas Piketty’s recent book, Capital, showed, the return on capital is higher than the return on labor. This trend will continue as technology advances. Income from capital, not earnings, predominates now at the top of the income distribution. So if you don’t have extra money to invest and can’t afford to live on the return of that investment, you have to work and your wage will be less than what you can make out of financial investment.
This is why Paul Krugman says we are entering a new gilded age.
So ok, this is what is happening in our world right now economically. What does that mean to libraries? We can see: (1) There will be a greater room for libraries to grow and contribute towards job-related continuing education and lifelong learning. (2) Libraries will have to play even a greater role in bridging the gap between the haves and the have-nots in terms of making information and technology resources available as widely and evenly as possible.
5. Education: Preparing the Future Workforce
It is entirely possible that the current trend of decreasing job opportunities and wages paired with increasing economic growth and productivity may reverse rather than continue. Some think that advances in artificial intelligence and broad technological development may create employment possibilities that we cannot yet begin to imagine.
But whichever way the future goes, one thing is clear. Education will be a key to the growth of employment opportunities and economic growth in the age of smart machines. Humans need to be able to work more efficiently operating or working alongside with machines. And this requires more education.
As we can see from this graph, the years of schooling at age 30 has been increasing steadily since 1875 until now, although the rate of increase slowed quite a bit since the 1950s.
One of the mundane but undeniable goal of education is preparing the future workforce. Higher education in particular is being more and more closely aligned with the needs of today’s businesses and industry than ever before.Even just a few decades ago, higher education used to be deemed as a rare opportunity and time to pursue learning for the sake of learning, explore the truth in knowledge. I doubt many college students of today hold this view, however.
Some even goes as far as placing the value of higher education solely in meeting the needs of the labor market. Just about a month ago, the Wisconsin Gov. Scott Walker called for a change in the university of Wisconsin’s mission statement in his state budget proposal with a $300 million cut . He suggested removing century-old language in the university mission statement such as “search for truth,†and “improve the human condition.†Instead, he suggested replacing them with “meet the state’s workforce needs.â€
Today’s businesses and industry prefer employees who come with the necessary skills that can be immediately put to use at work to those who need to be trained on the job. This is clearly seen in the practice of internships and an increasing number of certificate programs.
This has pushed higher education in the direction of vocationalism, and led some universities to experiment further with competency-based education. The basic idea of competency-based education is to graduate students equipped with proven skills that can be immediately applied at workplaces. This contrasts with the traditional credit-based education where students complete a certain number of credit hours before they graduate. Competency-based education is still new, but three big-ten universities – Michigan, Purdue and the Wisconsin— are already experimenting with this model.
Mitch Daniels, the president of Purdue University said: With its transdisciplinary, competency-based bachelor’s degree, “Businesses will not have to guess whether these students really are ready for the market, ready for their business, ready for the world†because the degree will be given for only those with proven competencies.
University of Michigan offers a new master’s of health professions education, which is both competency-based and distance-education. The Univ. of Wisconsin System’s “Flexible Option†offers five competency-based online credentials, which range from a certificate to bachelor’s degrees.
These competency-based education meets the changing needs of today’s businesses and industry and can potentially reduce the time and the cost of educational programs by utilizing learning analytics and other educational technology tools to track and measure students’ progress and skills obtained. Without these technology tools, competency-based education is not possible. In this new climate of the labor market, learning never really ends because workers are expected to constantly renew their skills. They have no choice but to become self-directed lifelong learners to stay employed.
The closer alignment between education and the labor market even influences the K-12 education. The influence of digital revolution and the idealization of the start-up culture is an important background of the ongoing discussion about whether children should learn how to code (meaning computer program) at school. STEM is being highlighted more than any other subjects these days. Makerspaces and 3d printing are being introduced as early as at the level of elementary schools.
6. The Maker Movement as a Game Changer for Creativity and Innovation
We have seen how the changing economic conditions are influencing today’s education. As librarians, we all are in the business of education. And the direction of today’s education deserves some serious reflection. (A) Where does a library stand when the greatest value of education is primarily found in obtaining successful employment? (B) What is the role of a library when education is reduced to merely equipping students with the skills that will make them hirable?
Of course, I fully expect that many of you would argue that this may be an exaggeration. After all, don’t we champion more creativity, innovation, and entrepreneurship than ever before in education and libraries? Don’t the maker movement and makerspaces, for example, demonstrate such things as creativity and innovation a great deal?
How about university-industry partnership and even libraries as start-up incubators? After all, many of us read articles and opinion pieces like this that argue for more industry-university partnership in higher ed and libraries as start-up incubators for budding entrepreneurs. Wouldn’t it be amazing if every library has a lively makerspace, where all library patrons make things, form a learning community, tap on their imagination and creativity, and plan and start their businesses, which further generate more jobs and bring us out of the economic stagnation?
Probably, it was this idea that the maker movement can revive economy and create more jobs that led the White House to host the first-ever Maker Faire last year. There, President Obama called the US ‘the nation of makers.’
I do not deny that there are great benefits in the industry-university partnership. There is also an undeniable positive value in the maker movement and 3d printing. 3D printing democratized manufacturing by allowing individuals without access to huge machines and a factory to design and make things that they want, often at a much lower costs than commercial products.
3D printing can make an ingenious idea into reality such as this 3d printed book for the blind. As we all know, makerspaces and 3d printers can be useful tools in hands-on learning, which can drastically improve students’ learning process and outcome.
It is also driving cutting-edge innovation in life sciences. Surgeons can now improve the success rate of a complicated surgery drastically by having a 3d printed parts of a patient’s body in advance and plan for individual differences. 3D printing can also be utilized to produce personalized medications for individuals without incurring huge costs as a result. We are also looking at tissue and organ 3d-printing, which will result in revolutionary advances in regenerative medicine.
This is Dr. Hack at University of Maryland, Baltimore, School of Dentistry. He teaches dental students digital dentistry. Digital dentistry means dentistry that uses new digital tools to improve the traditional dental treatment process. As you can see here, digital dentistry makes it possible to scan a patient’s tooth, create a digital scan of a crown, and then make the crown on the spot with a milling machine – similar to a 3d printer. Patients don’t have to hold the clay-like material in their mouth to create a mold and have a temporary filling done while waiting for the permanent crown is made. Digital dentistry drastically cuts down the time that a patient has to wait until the artificial tooth is made. In the past, this took 2-3 weeks. Digital dentistry enables dentists to complete the same process in only an hour or two.
7. What We Often Fail to See in the Mainstream Maker Movement
But there is another aspect to the maker movement and 3D printing that are rarely discussed and talked about. The maker movement was able to go mainstream in such a short time because it promises to deliver exactly what today’s businesses and industry need, the adaptable workforce. As a matter of fact, I think that the current maker culture represents the combination of neo-liberalism, techno-utopianism, the demand of the labor market for the adaptable workforce as the main background. Let me explain.
Thank about it. The kind of people who can spend hours and hours of their free time learning and doing 3d modeling and printing have certain advantages that a lot of people don’t. First, they have access to such technology. Second, they can afford investing their free time and money in learning such stuff. Third, they are already knowledgeable and tech-savvy enough to navigate this new technology scene and use it to their advantage.
But the current maker culture conveniently ignores all these differences that pre-exist between those makers and the rest. Instead, it simply depicts makers as the heroes of the ultimate freedom. Makers make things with their own hands, unlike the majority of those who simply consume things that are made by others. Makers are tech-savvy. And with their creativity and technical knowledge, they will not only innovate businesses, create more jobs, but also usher in more open and transparent society and culture for all of us to benefit. This is the promise of the idealized maker movement.
How wonderful would that be? Now we can all 3D-print our way to prosperity freedom. Only if it were so simple.
What is often overlooked, however, is that the current idealization of the maker culture unduly emphasizes individuals over systems & misplaces freedom where regulations are needed. It unfairly treats work as a hobby without pay, and spreads the unsustainable and unfair expectation that people should develop their skills constantly at their leisure outside of work.
This is neo-liberalism that ignores the issues of systematic inequality and reduces it to the matter of individual effort. The belief that technology can build a culture that is more transparent and open is techno-utopianism that tries to solve sociopolitical problems with technology alone. Instead, all we hear about the maker culture is how productive and innovative makers are. They are the future of the new “infinitely adaptable and flexible” workforce that the labor market is looking for.
8. Productivity Culture & Freedom to Self-Exploit
The most defining characteristics of our era are productivity and efficiency. These two have become a mantra in every realm of our life – corporate, public, labor, administrative, and education.And what accompanies productivity and efficiency is positivity and affirmation. We not only work harder to produce more and to be more efficient. We also do so with the can-do attitude, constantly ‘choosing’ to put more efforts towards work ‘with our own will.’ The current maker culture embodies all of these. We are all familiar with the statement that we are the managers of ourselves. Here, if we fail, all the faults lie with us, us alone.
Even those who write books are now expected to be more like entrepreneurs than writers. This Economist article describes how authors must be more businesslike than ever to succeed these days. Just writing well is not good enough any more.
But in the midst of all these frenzied pursuits for productivity and efficiency in new capitalism and its hyper-competition environment, people experience burnout and depression. Even though we long for the work-life balance, many of us take work to home and tie ourselves to our smartphones. We end up answering work e-mails around the clock no matter what our salaried work hours are. We and our society together even made business and exhaustion a kind of status symbol, an evidence of self-importance. Take a look at this presentation title in this year’s Code4Lib Conference “How to Hack it as a Working Parent: or, Should Your Face be Bathed in the Blue Glow of a Phone at 2 AM?.†This testifies to this struggle that all of us experiences.
What is interesting about our society is that we have such a strong belief that we are all ‘free’ agents in all aspects of our lives, that in order to make a better life, we exploit ourselves to an unprecedented degree. The harder it is to find traditional employment, the more tech-savvy, the more creative, the more productive, and the more innovative we have to become. And while doing so, we forget that we are also shaped and limited by something much bigger than us and that we do not always have control over.
Short of income? Why don’t we share our rides in Uber and share our guest bedroom through Airbnb while starting a new business at a garage? Here is our opportunity to participate in the global community of sharers and to contribute to the budding alternative sharing economy.
But the truth is that these new start-up businesses like Uber and Airbnb are operating in the realm where appropriate regulations and taxes are absent while unfairly competing with the existing taxi and hotel businesses. This is how a 26-year-old got the Uber bill of $362.57 for a 20 min. ride on the Halloween night after celebrating her birthday with friends. She couldn’t pay her rent after this bill. In Barcelona, Airbnb and Uber are in the middle of a controversy.
As German Philosopher Byyngchul Han wrote in his essay published in Süddeutsche Zeitung, “Anyone without money doesn’t have access to sharing. Even in the age of access, people without money remain shut out. Airbnb, the community marketplace that turns homes into hotels, even saves on hospitality. The ideology of community or collaborative commons leads to total capitalization of the community. Aimless friendship is no longer possible. In a society of reciprocal evaluation, friendliness is also commercialized. One is friendly to get a better ranking online. The harsh logic of capitalism prevails in the so-called sharing economy, where, paradoxically, nobody is actually giving anything away voluntarily.†(English translation from German)
And on the other hand, if you are a Uber driver, you don’t have any protection and labor rights that drivers from usual taxi companies may have. Because you are now an entrepreneur responsible for everything except paying the premium for using the Uber service to get your customers. You are free to boost your productivity and your efficiency. But you are all alone when the social safety net is needed.
9. The Limits of Personal Donations
I do not deny that technology achieves wonderful things. I sound like a cynic but I am not.
When the news of a Detroit man who walks 21 miles everyday to work was reported, donations poured in reaching at almost $350,000. The Humans of New York photographer who posts people’s photographs with their stories on Facebook raised over $1 million dollars for inner-city students.These would not have been possible without technological advances such as crowd-sourcing online platforms such as GoFundMe.
But these are non-systematic solutions to systematic and structural problems. What bothers me most is that there are more than one person who needs the mass transportation to get to work because they cannot afford a car, maintenance, and required insurance. There are more than one school that needs funding to provide better opportunities for children to experience the world outside of their small neighborhood. It’s not possible for us to organize fund-raising for each and every one of them. We need to build a system in which everyone can live a better life instead of rescuing a few selected individuals in a desperate need appealing to individuals’ good will and personal donations.
While crowd-sourced fund-raising such as these were well-meant by all means, it is an unsustainable solution to a systematic problem whose solutions should not be found in individual donations. Such solution can lead to avoiding more fundamental questions, such as why the established political, economic and legal systems resulted in the lack of mass transportation that people need to get to their workplaces in the first place, and how we can address those issues systematically.
10. The Role of Libraries is Never Apolitical.
Just like those crowd-sourced fundraising campaigns, as an educational institution, the role of libraries is never apolitical. The more prevalent and powerful an ideology is, the harder it is to discern and critique its influence on us. Whether we like it or not, schools, colleges, and libraries will continue to operate as an an agency to make students and patrons more hirable by improving their skills and providing more information, more resources, and more exposure to technology. The relationship of economic exchange in education – that is, students as clients and knowledge/skills as commodities – will continue and accelerate.
Cathy Eisenhower and Dolce Smith wrote in their book chapter “The Library as Stuck Place: Critical Pedagogy in the Corporate University,†the following: “In the current climate of accountability and austerity, libraries have become veritably “obsess[ed] with quantitative assessment, student satisfaction, outcomes, and consumerist attitudes towards learning.â€â€
We can understand how we got there. But that does not mean that we need to stay there. We do not want knowledge to be treated as mere commodities. We do not want learning to be reduced to mere transactions that will build up to just enough competencies to make our patrons hirable. For that, we need to first and foremost understand that the role of libraries is never apolitical.
11. Libraries as a Socially Meaningful and Responsible Public Institution
Libraries need to find ways to establish their stance as a socially meaningful and responsible public institution and reflect that in the ways they operate. We should be able to serve library patrons with the full understanding of the current socioeconomic and political conditions that shape libraries and their fiscal realities. After all, ideologies are human constructs. They can be changed, but only when we understand them. This is why libraries value knowledge and understanding.
One of the founding theorists of critical pedagogy, Henri Giroux said “… one of the fundamental tasks of educators is to make sure that the future points the way to a more socially just world, a world in which critique and possibility —in conjunction with the values of reason, freedom, and equality— function to alter the grounds upon which life is lived.â€
We celebrate and advocate creativity and innovation not just for more productivity and economic growth. The goal of productivity and growth cannot be more productivity and growth. Productivity and growth do not have an inherent value. The fact that we find this hard to accept testifies how steeped we are in the productivity culture.
As library technologists, we should ensure that our application of technology works towards altering the grounds upon which life is lived ‘for the better,’ not worse. As library technologists, we need to pay particularly close attention to the way technologies are meshed with ideology and what effect it has on the library’s mission and our patron’s lives. Technology is a powerful tool for boosting productivity and enabling innovation. But it loses its value when such productivity and innovation is pursued blindly.
12. Challenges for Libraries
There are challenges in re-establishing libraries as a more socially responsible and meaningful institution, however. In her blog post in Inside Higher Ed, Barbara Fister wrote “Surveys that Ithaka conducts periodically of faculty and of library directors show a growing gap in our beliefs about what libraries are for. Increasingly, library directors (with the exception of those at research libraries) assign more importance to the learning that happens in libraries and less to maintaining collections. (On the other hand) Faculty surveyed think the most important role of the library is the provision of the information they want for their research and teaching.â€
Fister perceptibly notes that the new ACRL Framework for Information Literacy articulates how ambitious librarians are about the kind of learning that academic librarians want to promote. This framework indeed intends to teach students how to think about information and help them understand that information and knowledge are socially constructed. Here what librarians set out to achieve in educating our library patrons, so that they can effectively and consciously navigate today’s complex information landscape, goes beyond the traditional expectation of our library stakeholders.
(As a side note, it would be worthwhile to think about how this ACRL framework for information literacy translates to the realm of technology. Just as with information, understanding the social context and effects of the technology adoption and use becomes more and more critical as technology pervades our daily lives.)
I believe that the changing focus of libraries from collections to learning, particularly ‘critical learning,’ is the right one. I also believe that librarians have been successfully developing more innovative ways to make that learning happen in a more relevant and exciting manner to patrons.
Here, for example, librarians at Mount Holyoke College Library in MAÂ and Whittier College Library in CAÂ organized Exciting Food workshop. This workshop was designed to familiarize students with various citation styles. Librarians showcased the citations of the recipes for each snack and the recipes came from a range of sources from books, websites, magazines to archival materials.
The Toronto Public Library now let library patrons to check out other humans at its “Human Library†event. The idea of the Human Library first emerged about a decade ago. It was designed to promote dialogue, reduce prejudices and encourage understanding by informally talking to “people on loan†who come from various backgrounds. The Toronto Public Library held its first Human Library event at five branches on Nov. 6, attracting more than 200 users who checked out the likes of a police officer, a comedian, a sex-worker-turned-club-owner, a model and a survivor of cancer, homelessness, and poverty.
The Human Library project suggests a way in which libraries that primarily deal with knowledge and information can at the same time operate as a more socially responsible and meaningful institution in the community, not just providing the best value for money for borrowed books, other resources, and library services. In this climate of the commodification of education and the constant demand on libraries to prove its ROI value, it will be a long way to hash out the details of the library operation that will achieve such a goal – going beyond equipping patrons with desired job skills and providing just necessary information resources.
But here are some pointers that libraries can take from other fields.
13. Ideas from Fields Outside of Libraries
Design and Violence is a project by the Museum of Modern Art in NYC. It curates and presents selected design objects and invite experts from fields as diverse as science, philosophy, literature, music, film, journalism, and politics to respond to those design objects and spark a conversation with all readers.
Here is an example post by Steve Pinker, Harvard College professor and a well known psychologist. He writes about a million dollar block. A million dollar block refers to a single city block, residents from which are incarcerated and states are spending in excess of a million dollars a year to keep them in jail. 1 million dollars just for the residents of a single city block because the concentration of the incarcerated in those blocks are that high. These maps of those “million dollar blocks†show the city-prison-city-prison migration flow in five of the nation’s cities.
In a different post, Alex Vitale, a Brooklyn College professor, discusses a civil disobedience suit designed to be worn by street protesters equipped with a wireless camera on the head and a speaker on the chest to protect them from police batons. Not necessarily practical but quite symbolic.
Here, the National Aquarium and Climate Central in Baltimore invite Maryland middle and high school students to participate in a contest that examines the impacts of climate change.
Biohackers are developing low-cost and non-toxic ink from bacteria as an alternative to toxic and costly commercial ink. Boihackers are known for seeking solutions to significant problems, which are not addressed by big pharmaceutical or biotechnology companies because they are not sufficiently profitable.
“Be My Eyes” App invites sighted people to sign up to help the blind to be their eyes in the time of need. You can help the blind through this mobile app with things such as if a blind person turned off the bathroom light indeed or if she or he is safe to cross the busy intersection when the traffic lights are broken.
When libraries consider in which direction they will pursue their next exciting project, remembering that libraries can act as a more socially responsible and meaningful institution than now as well as an information & knowledge sharing institution – while pursuing that project- can make a big difference.
We live in an increasingly racially segregated residential communities. This article in VOX shows that residential segregation rose dramatically throughout the US over the first half of the 20th century. This graph demonstrates this dramatic rise of county-level segregation in 1880 and 1940 for the Eastern US. All areas of the US experienced rising residential segregation levels, both North and South as well as urban and rural.
We also increasingly live a filter bubble which makes us blind to the perspectives and opinions different from ours. This is the result of personalized relevance rankings by search engine companies like Google and Yahoo. This is shown when we search for BP, for example, one of us gets the news results about BP’s oil spills while the other only gets the BP’s stock prices and the company information.
We also live in the times in which more and more micro-power structures are being openly questioned. Many of you would have seen this Rumblr titled “Men taking up too much space on the train†and thought “wow finally people are speaking up.†Similarly “mansplanation†has become a legitimate word that refers to the phenomenon in which men assume they know more when they are talking to women when they actually don’t. These are not new phenomena. These have been happening for decades. But we have been silent about them for many many years. Same-sex marriage is legal now in 37 states. Sexists remarks are no longer tolerated in professional conferences. A racist tweet can literally cost someone a job just in a flight’s time. As shown in the Ferguson story, current news reach us days earlier through the social media than through the mass media. As you can see here, the Ferguson story started appearing in Twitter on Saturday Aug 9, 2014 while the cable news networks didn’t get the first report out until Monday Aug 11,2014.
Libraries can play a pivotal role in educating people in areas that are neglected by other institutions such as filter bubble, residential segregation, assistive technologies, the awareness of environmental issues, and socioeconomic/ political problems in communities.
I believe that libraries can be a little bit like the Left Shark that did its own thing and was widely appreciated and adored.
In the beginning of this keynote I asked “many institutions advocate technology and innovation; how are libraries different?” This is our time to answer that question.
14. Librarianship Is All about Money and Power.
Lastly, I want to read you this anecdote from a wonderful article I recently read. This anecdote is about a librarian.
“One of my colleges is a quiet, diminutive lady, who might call up the notion of Marion the Librarian. When she meets people at parties and identifies herself, they sometimes say condescendingly, “A librarian, how nice. Tell me, what is it like to be a librarian?” She replies, “Essentially it is all about money and power.”
Where else other than at libraries, shall we find the critical distance for reflecting on today’s constant push for productivity and efficiency?
(This was written to be more as my notes, and so it is not the exact script of my talk. But hopefully, it would be still useful to some folks. All the references in my slides were given as URLs in each slide, and you can grab them all easily in the “Transcripts” section on my slides in Slideshare.net.)
Slides