If you do coding, you will be making lots of tiny little changes to a file. You are also likely to be working on multiple computers at different locations. For documents and other types of files, we often use Dropbox or Google Drive/Docs. Tools like Dropbox and Google Drive/Docs are central repositories, and they allow you to always keep the most up-to-date version of the file, make changes to it, save it, and then access it at another computer. Dropbox and Google Drive/Docs also supports version-control. With those tools, you can review changes and revert to the previous state of file if you would like.
BitBucket is a tool similar to Dropbox. And it works with Git. Git is is a distributed revision control and source code management (SCM) system.  GitHub, which is another version-controlled repository web site is popular among coders and also uses Git. (If you want to try this with GitHub, the process is pretty much the same, but you may want to start by cloning somebody’s existing repo. Check out this ACRL TechConnect post by Eric.) BitBucket is similar to GitHub but it allows a completely private repository which is not supported in the free GitHub plan. So if you are working on stuff and don’t want them to be seen publicly until you are ready to release, BitBucket is a good choice.
In this post, I will show you the very basic commands of Git and how I make changes to files, sync my local repository with the BitBucket repository, add/commit them to my local repo and push them to the remote repo in BitBucket for those who are not familiar with Git. Here, I assume that you already have git installed and set up a repository in BitBucket. If not, there are many tutorials online and also the instruction you get after signing up for BitBucket is quite clear and straightforward.
Once you are all set, the first step I run in my repo is always status command. When I type in git status in the command line (I am using Terminal in Mac), git shows in red that in my repo there are two files that I modified but have not committed. This means that the files were added, meaning they were explicitly added by the git add command but changed without being committed. You can make all sorts of changes to files but until you run the git commit command, it is sort of not official and you cannot push your changes and sync your updated files in the local repo with the remote repo.
**If the image is blurry, just double-click it and you will be able to see the clear version.**
git status
But I also vaguely remember that I worked on some files in this remote repo from home several days ago and pushed the changes. Those changes have not yet been reflected in my local repo at my work computer. So I want to sync my local repo with the remote repo first, which has more up-to-date files. To do this, I run the following command. This literally pulls in all the changes from the remote repo to my local repo. And after a few seconds, you get the message that everything went well and you are good to go.
git pull origin master
Now at this point, I can start work on all the up-to-date files. So I go ahead and make some more changes to the two files – bkmklt.html and link.html. After that, I am ready to make the changes official, I run the commit command. You can type in a specific file name you want to commit or you can just use a dot to make Git to commit all modified files. The commit command requires a commit message. So you have to add some message at the end. Here I write that I removed some comment lines. The message is more important if the change is for other people but try to make it as specific as possible.
If I have created a completely new file in my local repo (that is a designated folder where I set up a Git repo), I will have to add the file first in order to be able to commit it. You can do so by git add filename.xyz and you should be ready to commit it. If you want to add all new files you can also use a dot (.)Â instead of a file name.
Below, I ran the status command again before running the commit command.
git commit . -m “removing some comment lines”
So the modified files have been committed now. But they are still in my local repo. If I want to get to them later from another computer however, I need to sync these files with the central repo in BitBucket. The push command does that. You are pushing out your local changes into the remote repo here. If all goes well, you will get the success message as shown below. (Type in your BitBucket password when prompted.)
git push origin master
The change is also recorded in my BitBucket account page.
I can also view the changes I made in BitBucket. The red part means what I deleted and the green part means what I added.
Now when I go home and want to work on these files, I will start with “git pull origin master” to sync my home computer with the remote that is up-to-date.
It is really very much like Dropbox or Google Docs except that you get to type in lots of commands. I hope this will help those who are curious about Git but somewhat intimidated by the command lines! So try it out if you are curious.
*** This post has been originally published in ACRL TechConnect on Mar. 13, 2013. ***
Many librarians work with technology even if their job titles are not directly related to technology. Design is somewhat similar to technology in that aspect. The primary function of a librarian is to serve the needs of library patrons, and we often do this by creating instructional or promotional materials such as a handout and a poster. Sometimes this design work goes to librarians in public services such as circulation or reference. Other times it is assigned to librarians who work with technology because it involves some design software.
The problem is that knowing how to use a piece of design software does not entail the ability to create a great work of design. One may be a whiz at Photoshop but can still produce an ugly piece of design. Most of us, librarians, are quite unfamiliar with the concept of design. ACRL TechConnect covered the topic design previously in Design 101 – Part 1 and Design 101 – Part 2. So be sure to check them out. In this post, I will share my experience of creating a poster for my library in the context of libraries and design.
1. Background
My workplace recently launched the new Kindle e-book leader lending program sponsored by the National Network of Libraries of Medicine/Southeast Atlantic Region Express Mobile Technology Project. This project is to be completed in a few months, and we have successfully rolled out 10 Kindles with 30 medical e-book titles for circulation early this year. One of the tasks left for me to do as the project manager is to create a poster to further promote this e-book reader program. No matter how great the Kindle e-book lending program is, if patrons don’t know about it, it won’t get much use. A good poster can attract a lot of attention from library patrons. I can just put a small sign with “Kindles available!” written on it somewhere in the library. But the impact would be quite different.
2. Trying to design a poster
When I planned the grant budget, I included an budget item for large posters. But the item only covers the printing costs, not the design costs. So I started designing a poster myself. Here are a few of my first attempts. Even to my untrained eyes, these look unprofessional and amateurish, however. The first one looked more like a handout than a poster. So I decided to make the background black. That makes the QR code and the library logo invisible however. To fix this, I added a white background behind them. Slightly better maybe? Not really.
My first try doesn’t look so good!
My second attempt is only marginally better!
One thing I know about design is that an image can save or kill your work. A stunning image alone can make a piece of design awesome. So I did some Google search and found out this nice image of Kindle. Now it looks like that I need to flip the poster to make it wide.
The power of a nice image! Too bad it is copyrighted…
But there is a catch. The image I found is copyrighted. This was just an example to show how much power a nice image or photograph can have to the overall quality of a work of design. I also looked for Kindle images/photographs in Flick Creative Commons but failed to locate one that allows making derivatives. This is a very common problem for libraries, which tend to have little access to quality images/photographs. If you are lucky you may find a good image from Pixabay which offer very nice photographs and images that are in public domain.
Changed the poster setup to to make it wide.
3. What went wrong
You probably already have some ideas about what went wrong with my failed attempts so far. The font doesn’t look right. The poster looks more like a handout. The image looks amateurish in the first two examples. But the whole thing is functional for sure, some may say. It does the job of conveying the message that the library now has Kindle E-book readers to offer. Others may object. No, not really, the wording is vague, far from clear. You can go on forever. A lot of times, these issues are solved by adding more words, more instructions, and more links, which can be also problematic.
But one thing is clear. These are not pretty. And what that means is that if I print this and hang up on the wall around the library, our new Kindle e-book lending program would fail to convey certain sentiments that I had in mind to our library patrons. I want the poster to present this program as a new and exciting new service. I would like the patron to see the poster and get interested, curious, and feel that the library is trying something innovative. Conveying those sentiments and creating a certain impression about the library ‘is’ the function of the poster as much as informing library patrons about the existence of the new Kindle e-book reader lending program. Now the posters above won’t do a good job at performing that function. So in those aspects, they are not really functional. Sometimes beauty is a necessity. For promotional materials, which libraries make a lot but tend to neglect the design aspect of them, ‘pleasing to the eyes’ is part of their essential function.
4. Fixing it
What I should have done is to search for examples first that advertise a similar program at other libraries. I was very lucky in this case. In the search results, I ran into this quite nice circulation desk signage created by Saint Mary’s College of Maryland Library. This was made as a circulation desk sign, but it gave me an inspiration that I can use for my poster.
An example can give you much needed inspiration!
Once you have some examples and inspiration, creating your own becomes much easier. Here, I pretty much followed the same color scheme and the layout from the one above. I changed the font and the wording and replaced the kindle image with a different one, which is close to what my library circulates. The image is from Amazon itself, and Amazon will not object people using their own product image to promote the product itself. So the copyright front is clear. You can see my final poster below. If I did not run into this example, however, I would have probably searched for Kindle advertisements, posters, and similar items for other e-book readers for inspiration.
One thing to remember is the purpose of the design. In my case, the poster is planned to be printed on a large glossy paper (36′ x 24′). So I had to make sure that the image will appear clear and crisp and not blurry when printed on the large-size paper. If your design is going to be used only online or printed on a small-size item, this is less of an issue.
Final result!
5. Good design isn’t just about being pretty
Hopefully, this example shows why good design is not just a matter of being pretty. Many of us have an attitude that being pretty is the last thing to be considered. This is not always false. When it is difficult enough to make things work as intended, making them pretty can seem like a luxury. But for promoting library services and programs at least, just conveying information is not sufficient. Winning the heart of library patrons is not just about letting people know what the library does but also about how the library does things. For this reason, the way in which the library lets people know about its services and programs also matters. Making things beautiful is one way to improve on this “how” aspect as far as promotional materials are concerned. Making individual interactions personally pleasant and the transactions on the library website user-friendly would be another way to achieve the same goal. Design is a broad concept that can be applied not only to visual work but also to a thought process, a tool, a service, etc., and it can be combined with other concept such as usability.
Resources
While I was doing this, I also discovered a great resource, Librarian Design Share. This is a great place to look for an inspiration or to submit your own work, so that it can inspire other librarians. Here are a few more resources that may be useful to those who work at a library and want to learn a bit more about visual design. Please share your experience and useful resources for the library design work in the comments!
From Flickr: http://www.flickr.com/photos/21232564@N06/2234726613/
Many of us – librarians – are members of some professional organizations. We tend to join one and pay dues every year but don’t do much about or with those organizations beyond that. But that would be probably not the best way to make use of your professional organization. In order to best utilize your organization, you need to know what it does first and see if their activities fit with your interests. So do some research to see if it is a good fit for you. Secondly, you need to figure out how the organization works, what structure it has, what is the mode of operation, etc.
What interest groups does it have?
What kind of programs does it put up at conferences?
What committees does it have?
Who belong to the organization and what do they do for the organization?
What is the procedure for being involved with an IG or becoming a member of a committee (and the timeline)?
Is there a mentoring program?
What are, if any, tangible benefits for being a member?
Is there a board?
What does the board do?
What is the relationship between the board and the members?
Who do I contact if I have a suggestion?
I confess that I do not know the answers to all these questions for all organizations that I am a member of. I only got to know about a few organizations a little, while I was doing things that were of interest to me. But I think that organizations need to make answers to these questions as clear and transparent as possible to current and potential members and that members should also demand that organizations do so if not.
That having been said, here are some thoughts of mine about the organization that I have been involved for a while: LITA (Library Information Technology Association), a division of ALA (American Library Association). Andromeda Yelton, who is running for the the LITA board of directors, is interviewing many librarians involved with LITA as part of her campaign. I think it is a great project for not just those who are in the LITA leadership positions but also those who are interested in LITA and want to hear from other people’s thoughts on LITA as an organization. I am recording the video interview with Andromeda tomorrow, but I thought Andromeda’s three questions would be interesting to many others as well.  So you can check out my answers here if you prefer reading a write-up to watching a video (as I do). If you are a member of ALA and are interested in LITA, hopefully this will be useful. If your primary organization is not LITA, you can think about that other organization instead and think about how your organization does compared to LITA.
How did you get involved with LITA?
I went to the 2009 ALA Annual Conference in Chicago. That was my very first ALA conference, and at that time I had zero understanding about the structure of ALA such as a division, a roundtable, a committee, an interest group (IG) etc. But while I was planning what programs to attend, LITA kept popping up. And then I happened to go to this meeting of LITA Emerging Technologies IG, and there were maybe three dozens of librarians who were very much like me, early in their career, doing technology stuff, and was somewhat confused about this new title of Emerging Technologies Librarian and the job duties of this title. We had a fantastic conversation, and I ended up volunteering to put together the resources we discussed after the program. I eventually wrote a program proposal on the topic for the next ALA Annual conference with the vice-chair of that IG at that time, Jacquelyn (Erdman) after the conference. It got accepted, and so Jacquelyn and I put together the program for the 2010 ALA Annual, “What Are Your Libraries Doing about Emerging Technologies?†which was amazingly well received. So that was my first experience of getting involved with LITA at an active level. In 2010, I also volunteered to chair the quite new Mobile Computing Interest Group because the first chair, Cody (Hanson) was steeping down. So that’s how I started being involved with LITA.
At that time, I didn’t think that I was getting involved with LITA. I was just doing things that were interesting to me. But this is just my experience. There are many different ways to be involved with LITA. For example, I have a friend who joined LITA and then e-mailed to the LITA president asking to put him on a LITA committee. He was put on a committee almost immediately and then later also became an ALA Emerging Leader sponsored by LITA. So you can do that. Not many people would think of e-mailing the LITA president with a request for a committee spot. That’s out-of-the-box thinking! Some people also start by creating an Interest Group and/or by going to the LITA Happy Hour, which is also an excellent way to be involved with LITA.
What are the strengths of LITA?
LITA is a very big group because it is a division of an even bigger organization, ALA. So there are a great number of people who deal with technology at many different levels in many different types of institutions: public libraries, academic libraries, special libraries, small libraries, large libraries, system administrators, web masters, IT department heads, metadata librarians, etc. So you are almost guaranteed to meet fascinating people whom you did not know about and they always have interesting ideas and thoughts on the current trends of library technology.
Another strength of LITA that I see is its Interest Group(IG)s. There are a great number of them, and they are highly informal and welcoming to new members. If you cannot find a LITA IG you like, you can even start one yourself with not much effort. I know that many people gravitate towards bigger programs because IG meetings don’t always post a clear agenda in advance. But that is a mistake. You are more likely to learn about things you did not expect from IG meetings than from large programs.
I also think that the simplified program proposal process for the ALA Annual conference and the LITA Forum is a huge strength of LITA. It cuts down so many levels of bureaucracy, and this only has been implemented only recently (3 years ago or so I think). You just fill out a Google Form, and you don’t have to be even associated with LITA IG or even LITA (if I am correct) as long as the proposal is relevant to library technologies. (Now wouldn’t it be dreamy if we can simplify an organization’s structure just like that too? Just thinking…) The simplified procedure attracts more qualified potential speakers, thereby enriching the programs offered from LITA at conferences.
What are the challenges for LITA?
LITA members, particularly the new members, have an amazing amount of energy. I don’t think that LITA knows how to harness this energy to the maximum benefit to itself. I understand that there are existing structural and procedural practices, but those practices may be ill-suited for gathering and implementing the creative ideas from new members. A lot of times, what confuses and intimidates new LITA members are the structure and the operation of the organization. Now that I have been active with LITA for some years, it doesn’t seem too bad to me any longer! But this is probably what happened to many who lead LITA. They are probably too familiar to notice what barriers of entry exist to new members. You get used to it. So there needs to be a strong mechanism to get input from new members inside LITA and then do something about the input. LITA really needs to do more to reach out to new members to let them know what they can use LITA for and how to do so. It has gotten better over the years but it can still be much more improved.
Also, LITA has a few high-profile programs such as Top Tech Trends. So LITA is well-known at least to ALA members. But that popularity and recognition is connected to the strength of LITA only at a very abstract level. LITA needs to change that. I was one of the two LITA-sponsored ALA Emerging Leaders in 2010-2011, and my team did a big project about what to do to give a stronger brand and identity to LITA. And I am hoping to see that some of those ideas from our team project get picked up by the LITA leadership. I am also serving on the LITA Top Tech Trends committee and working on transforming the Top Tech Trends program into a more dynamic and participatory event. So far the idea was received with enthusiasm at the committee meeting last week. So we will see.
Overall, changes have been slow, and I think LITA members are not cut out for a slow process. They deal with very fast-paced information technology every day after all. So the speed of things getting done really needs to pick up to respond to the average high energy of LITA members.
Additional thoughts – Join or Not Join
I know that many people get put off by various things when they join LITA, or any other professional organizations. They feel that the organization is not welcoming enough, don’t do much for the benefit of individual members, seem to have an awful bureaucracy, have too many unproductive committees, and even have cliques. And probably all of these are true to a degree. But those cannot be changed immediately and it won’t help you in the mean time. Besides if you are interested in library technology and an ALA member, you cannot but cross paths with LITA at some point. So you might as well make the best out of it as much as you can. And that doesn’t necessarily entail being a member.
I think it is the best if people join an organization because it is actually useful to them. If you are interested in LITA, don’t just join and wait for things to happen. Start somewhere else instead. First check out the LITA listserv, go to LITA meetings and programs, meet with people in LITA, and see if something clicks with you, your interests, and what you want to do, learn, or try. If it does, then go ahead and do those things you want to do. While doing those things, if it turns out that you cannot proceed without joining LITA, then join it. Now you have something you are doing using the organization for your benefit. Consequently the membership will be worthwhile, and the organization will also benefit from your participation. This way the connection between you and the organization will be meaningful and concrete. And down the line after doing many things that excite you, perhaps when you get to care enough about the organization itself, you can also do some work for the organization itself to improve things that you did not not like much or to create things you would have liked to see.
*** This post has been originally published in ACRL TechConnect on Feb. 11, 2013. *** *** Update: Several references and a video added (thanks to Brett Bonfield) on Feb. 21, 2013. ***
Most famously, he was arrested in 2011 for the mass download of journal articles from JSTOR. He returned the documents to JSTOR and apologized. The Massachusetts state court dismissed the charges, and JSTOR decided not to pursue civil litigation. But MIT stayed silent, and the federal court charged Swartz with wire fraud, computer fraud, unlawfully obtaining information from a protected computer and recklessly damaging a protected computer. If convicted on these charges, Swartz could be sentenced to up to 35 years in prison at the age of 26. He committed suicide after facing charges for two years, on January 11, 2013.
Information wants to be free; Information wants to be expensive
Now, he was a controversial figure. He advocated Open Access (OA) but to the extent of encouraging scholars, librarians, students who have access to copyrighted academic materials to trade passwords and circulate them freely on the grounds that this is an act of civil disobedience against unjust copyright laws in his manifesto. He was an advocate of the open Internet, the transparent government, and open access to scholarly output. But he also physically hacked into the MIT network wiring closet and attached his laptop to download over 4 million articles from JSTOR. Most people including librarians are not going to advocate trading their institutions’ subscription database passwords or breaking into a staff-only computer networking area of an institution. The actual method of OA that Swartz recommended was highly controversial even among the strongest OA advocates.
But in his Guerrilla OA manifesto, Swartz raised one very valid point about the nature of information in the era of the World Wide Web. That is, information is power. (a) As power, information can be spread to and be made useful to as many of us as possible. Or, (b) it can be locked up and the access to it can be restricted to only those who can pay for it or have access privileges some other way. One thing is clear. Those who do not have access to information will be at a significant disadvantage compared to those who do.
And I would like to ask what today’s academic and/or research libraries are doing to realize Scenario (a) rather than Scenario (b). Are academic/research libraries doing enough to make information available to as many as possible?
Among the many articles I read about Aaron Swartz’s sudden death, the one that made me think most was “Aaron Swartz’s suicide shows the risk of a too-comfortable Internet.” The author of this article worries that we may now have a too-comfortable Internet. The Internet is slowly turning into just another platform for those who can afford purchasing information. The Internet as the place where you could freely find, use, modify, create, and share information is disappearing. Instead pay walls and closed doors are being established. Useful information on the Internet is being fast monetized, and the access is no longer free and open. Even the government documents become no longer freely accessible to the public when they are put up on the Internet (likely to be due to digitization and online storage costs) as shown in the case of PACER and Aaron Swartz. We are more and more getting used to giving up our privacy or to paying for information. This may be inevitable in a capitalist society, but should the same apply to libraries as well?
The thought about the too-comfortable Internet made me wonder whether perhaps academic research libraries were also becoming too comfortable with the status quo of licensing electronic journals and databases for patrons. In the times when the library collection was physical, people who walk into the library were rarely turned away. The resources in the library are collected and preserved because we believe that people have the right to learn and investigate things and to form one’s own opinions and that the knowledge of the past should be made available for that purpose. Regardless of one’s age, gender, social and financial status, libraries have been welcoming and encouraging people who were in the quest for knowledge and information. With the increasing number of electronic resources in the library, however, this has been changing.
Many academic libraries offer computers, which are necessary to access electronic resources of the library itself. But how many of academic libraries keep all the computers open for user without the user log-in? Often those library computers are locked up and require the username and password, which only those affiliated with the institution possess. The same often goes for many electronic resources. How many academic libraries allow the on-site access to electronic resources by walk-in users? How many academic libraries insist on the walk-in users’ access to those resources that they pay for in the license? Many academic libraries also participate in the Federal Depository Library program, which requires those libraries to provide free access to the government documents that they receive to the public. But how easy is it for the public to enter and access the free government information at those libraries?
I asked in Twitter about the guest access in academic libraries to computers and e-resources. Approximately 25 academic librarians generously answered my question. (Thank you!) According to the responses in Twitter, almost all except a few libraries ( mentioned in Twitter responses) offer guest access to computers and e-resources on-site. It is to be noted, however, that a few offer the guest -access to neither. Also some libraries limit the guests’ computer-use to 30 minutes – 4 hours, thereby restricting the access to the library’s electronic resources as well. Only a few libraries offer free wi-fi for guests. And at some libraries, the guest wi-fi users are unable to access the library’s e-resources even on-site because the IP range of the guest wi-fi is different from that of the campus wi-fi.
I am not sure how many academic libraries consciously negotiate the walk-in users’ on-site access with e-resources vendors or whether this is done somewhat semi-automatically because many libraries ask the library building IP range to be registered with vendors so that the authentication can be turned off inside the building. I surmise that publishers and database vendors will not automatically permit the walk-in users’ on-site access in their licenses unless libraries ask for it. Some vendors also explicitly prohibit libraries from using their materials to fill the Interlibrary loan requests from other libraries. The electronic resource vendors and publishers’ pricing has become more and more closely tied to the number of patrons who can access their products. Academic libraries has been dealing with the escalating costs for electronic resources by filtering out library patrons and limiting the access to those in a specific disciplines. For example, academic medical and health sciences libraries often subscribe to databases and resources that have the most up-to-date information about biomedical research, diseases, medications, and treatments. These are almost always inaccessible to the general public and often even to those affiliated with the institution. The use of these prohibitively expensive resources is limited to a very small portion of people who are affiliated with the institution in specific disciplines such as medicine and health sciences. Academic research libraries have been partially responsible for the proliferation of these access limitations by welcoming and often preferring these limitations as a cost-saving measure. (By contrast, if those resources were in the print format, no librarian would think that it is OK to permanently limit its use to those in medical or health science disciplines only.)
Too-comfortable libraries do not ask themselves if they are serving the public good of providing access to information and knowledge for those who are in need but cannot afford it. Too-comfortable libraries see their role as a mediator and broker in the transaction between the information seller and the information buyer. They may act as an efficient and successful mediator and broker. But I don’t believe that that is why libraries exist. Ultimately, libraries exist to foster the sharing and dissemination of knowledge more than anything, not to efficiently mediate information leasing.  And this is the dangerous idea: You cannot put a price tag on knowledge; it belongs to the human race. Libraries used to be the institution that validates and confirms this idea. But will they continue to be so in the future? Will an academic library be able to remain as a sanctuary for all ideas and a place for sharing knowledge for people’s intellectual pursuits regardless of their institutional membership? Or will it be reduced to a branch of an institution that sells knowledge to its tuition-paying customers only? While public libraries are more strongly aligned with this mission of making information and knowledge freely and openly available to the public than academic libraries, they cannot be expected to cover the research needs of patrons as fully as academic libraries.
I am not denying that libraries are also making efforts in continuing the preservation and access to the information and resources through initiatives such as Hathi Trust and DPLA (Digital Public Library of America). My concern is rather whether academic research libraries are becoming perhaps too well-adapted to the times of the Internet and online resources and too comfortable serving the needs of the most tangible patron base only in the most cost-efficient way, assuming that the library’s mission of storing and disseminating knowledge can now be safely and neutrally relegated to the Internet and the market. But it is a fantasy to believe that the Internet will be a sanctuary for all ideas (The Internet is being censored as shown in the case of Tarek Mehanna.), and the market will surely not have the ideal of the free and open access to knowledge for the public.
If libraries do not fight for and advocate those who are in need of information and knowledge but cannot afford it, no other institution will do so. Of course, it costs to create, format, review, and package content. Authors as well as those who work in this business of content formatting, reviewing, packaging, and producing should be compensated for their work. But not to the extent that the content is completely inaccessible to those who cannot afford to purchase but nevertheless want access to it for learning, inquiry, and research. This is probably the reason why we are all moved by Swartz’s Guerrilla Open Access Manifesto in spite of the illegal implications of the action that he actually recommended in the manifesto.
Knowledge and information is not like any other product for purchase. Sharing increases its value, thereby enabling innovation, further research, and new knowledge. Limiting knowledge and information to only those with access privilege and/or sufficient purchasing power creates a fundamental inequality. The mission of a research institution should never be limited to self-serving its members only, in my opinion. And if the institution forgets this, it should be the library that first raises a red flag. The mission of an academic research institution is to promote the freedom of inquiry and research and to provide an environment that supports that mission inside and outside of its walls, and that is why a library is said to be the center of an academic research institution.
I don’t have any good answers to the inevitable question of “So what can an academic research library do?” Perhaps, we can start with broadening the guest access to the library computers, wi-fi, and electronic resources on-site. Academic research libraries should also start asking themselves this question: What will libraries have to offer for those who seek knowledge for learning and inquiry but cannot afford it? If the answer is nothing, we will have lost libraries.
In his talk about the Internet Archive’s Open Library project at the Code4Lib Conference in 2008 (at 11:20), Swartz describes how librarians had argued about which subject headings to use for the books in the Open Library website. And he says, “We will use all of them. It’s online. We don’t have to have this kind of argument.” The use of online information and resources does not incur additional costs for use once produced. Many resources, particularly those scholarly research output already have established buyers such as research libraries. Do we have to deny access to information and knowledge to those who cannot afford but are seeking for it, just so that we can have a market where information and knowledge resources are sold and bought and authors are compensated along with those who work with the created content as a result? No, this is a false question. We can have both. But libraries and librarians will have to make it so.
Videos to Watch
“Code4Lib 2008: Building the Open Library – YouTube.â€
“Aaron Swartz on Picking Winners” American Library Association Midwinter meeting, January 12, 2008.
“Freedom to Connect: Aaron Swartz (1986-2013) on Victory to Save Open Internet, Fight Online Censors.â€
REFERENCES
“Aaron Swartz.†2013. Accessed February 10. http://www.aaronsw.com/.
I recently read this article “Sitting Is the Smoking of Our Generation” from Harvard Business Review Blog recently. And I couldn’t agree more. Like many, I spend long hours at the desk ‘sitting’. I sometimes sit all my eight hours of work in the office chair (not even a fancy ergonomic one) working through lunch until I go home. When this happens, which is often, it really doesn’t help my productivity nor my mood. My mind fears to take a break once I am glued to the computer screen although I also know in full that it is counter-productive. My Outlook keeps beeping every five minutes with new emails. My calendar shows a series of meetings. I become a slave to the computer and the office chair everyday. So when I read this, I thought I need to take an action to break this habit for real.
As we work, we sit more than we do anything else. We’re averaging 9.3 hours a day, compared to 7.7 hours of sleeping. Sitting is so prevalent and so pervasive that we don’t even question how much we’re doing it. And, everyone else is doing it also, so it doesn’t even occur to us that it’s not okay. …… Of course, health studies conclude that people should sit less, and get up and move around. After 1 hour of sitting, the production of enzymes that burn fat declines by as much as 90%. Extended sitting slows the body’s metabolism affecting things like (good cholesterol) HDL levels in our bodies. Research shows that this lack of physical activity is directly tied to 6% of the impact for heart diseases, 7% for type 2 diabetes, and 10% for breast cancer, or colon cancer. You might already know that the death rate associated with obesity in the US is now 35 million.
So what can I do? Here are a few things I did. A while ago, I ran into this idea of a standing desk to reduce some of the hours we spend sitting. I can use a laptop at work and I have a bookshelf in my office. So I emptied two top rows of the bookshelf in the office and removed one top shelf. But the problem was I was rarely standing up to even do this. If you don’t get off the chair, there is no way you are going to use this.
For this reason, this time around, I also decided to add a timer. When I arrive in the office, I turn this on and set it to ring a bell every 60 minutes during my 8 hours of work. When the bell rings I get up and move around for a few minutes or use a standing desk even if it is only for 10 minutes. I like the sound of the meditation bell. So I use a meditation timer but you can use any timer for this, either on your work computer or on your smartphone. I set the timer program, so that it would run automatically whenever I power up the work laptop. And all I need to do is to just press the start button once a day. Easy!
Lastly, I turned off my new e-mail notification in my work e-mail. The frequent beep from my email has been always breaking my concentration and I realized that I am most productive if I can just do work without checking my emails. But like many people, I could not habituate myself to check work e-mails only two or three times a day and people often expected my replies in an hour or less. But by turning off the notification sound, at least I was not being interrupted when I was in the middle of doing something.
These three simple things I did – a standing desk, a timer reminder, turning off the new e-mail notification beeping sound -so far have been successful in making me move a bit more and preventing me from sitting for eight hours straight and leaving the office physically miserable and mentally tired at the end of the day.
If you have any other simple tricks that work well to make you sit less and move more during your office hours, please share in the comments!
I have been invited to speak as a panelist for the American Libraries Live Episode 2 on Thursday, January 10th at 2pm EST. Since this program will feature David Connolly, who manages the ALA JobList site (which every budding librarian should know about), and Jill Klees, a Career Liaison who works with the San Jose State University School of Library and Information Science, it is going to be informative for sure. So if you are looking for your first librarian position or getting ready for job search, make sure to tune in.
Previously, I wrote about personal branding for new and budding librarians and interviewed a few librarians for my blog who were successful in landing their first librarian job. (Search for ‘Interview with brand-new librarians’ in the search box on the right if you want to check them out. The links are also at the end of this post.) But for the last four years or so, I had opportunities to serve on several search committees, to hire many library assistants myself, and to be at many candidate interviews and presentations. So, in this post I would like to share several things that I have learned about library job search from the other side of the table, that is, not the job-seeking but the hiring side.
As everyone knows, job search is a stressful process. You may have been searching for a job for a long time. You may have been without a job for a while. You may have been selected many times for a phone or in-person interview only to hear that the job went to someone else. You may even had been offered a job and then told that the position was canceled last minute for the budget issues. You will be anxious and worried about the future. You might even doubt if any library will ever offer you a job. You may start to feel desperate and depressed. Well, this is not just you but something that almost everyone goes through a job search process. But still, that won’t cheer you up much while you are still looking for a job. The worst part of job search is the feeling that you are powerless.
But what I have learned from being at the hiring side of the table is that this is not necessarily the case. The hiring process is just as stressful to an employer as the job search process is to a job applicant. There are many misconceptions that job applicants tend to subscribe to but are not necessarily true. Here are several of them, and I will explain why these are misconceptions even though each of them may appear pretty convincing. Hopefully this will help you to get a more balanced view about the whole process than I had and reduce some of the anxiety and stress you are bound to feel during the job search.
1. Since my MLIS degree is brand-new, I won’t stand a chance competing with more experienced librarians applying for the same position, right? No.
This is common fear that many new LIS graduates have. But the truth of the matter is that many employers actually prefer new graduates to experienced librarians for a variety of reasons. Many employers think that new LIS graduate are likely to be (a) more up-to-date with new library trends, (b) more capable with technology, and (c) more enthusiastic and energetic. These are great strengths to many employers’ eyes. Now it is up to you to show them that all these strengths apply to you. Sometimes, employers explicitly look for candidates with a specific amount of work experience in a particular field. But if that is the case, the job positing will clearly state so. If no such condition is found in the posting however, you can safely assume that new graduates are welcome to apply.
So don’t worry in advance whom you are going to be competing with. Instead, focus on what contribution you can make to the position if you are selected.
2. I will be at a disadvantage if I don’t want to relocate. I will be at a disadvantage if I apply for a job far away from where I currently reside. Right? Not really.
Generally, finding a job can take less time if you are willing to relocate. However, it is also true that many employers prefer to hire local candidates for a variety of reasons. Many employers are willing to fly qualified candidates across the continent for an interview as long as a candidate has qualifications they want. But some employers like to save expenses involved with bringing in a candidate from far away. In such cases, you may get invited for an interview even if you are not the top candidate because there is little cost involved. Sometimes, it is not expenses that make employers prefer local candidates. They may be interested in those who are more likely to stay with them rather than leaving after a few years of service. They may want someone who is more familiar with the local culture and environment.
The point is that many employers will make different decisions based upon different considerations at different times. Those considerations are almost impossible for a job candidate to predict. So my advice is to simply apply for the positions that match your experience and skill set. If you are willing to relocate, apply for out-of-state jobs. If you are unwilling or unable to relocate, then focus on the jobs available in your area and don’t worry about others. Â Do your best at what you can do, and do not worry about things that you have no control over.
3. Applying for as many jobs as possible will increase the chance of landing a job. No.
This seems to be simple enough. The more jobs you apply for, the more chances you will have in getting an interview at least, right? Well, unfortunately, finding a job is not like winning a lottery. The fact that you submitted your resume and cover letter has almost nothing to do with the chance of being considered as a candidate for the position. You will be considered so only if your resume and cover letter actually show that you are qualified for and likely to be a good fit for the position. Otherwise, the act of submitting an application is just a waste of time. I know that many send in applications to jobs that they are remotely qualified for or are not even half-enthusiastic for the reason of ‘just in case.’ This is understandable, but what it does is to lessen your anxiety by giving you a false sense of doing everything you can more than to actually raise your chance of being called for interviews and getting actual job offers.
Therefore, invest your time and energy in selecting the most relevant jobs to your qualifications and in making your applications for those jobs as good as they can be. This takes time and focus, and you cannot maintain this level of perfection if you are applying for as many jobs as possible. It will be hard, but be wise and selective in applying for positions, so that when you do apply you can give all you got.
4. In order to get the job offer, I have to meet ‘all’ the qualifications in the job posting. No.Â
A job posting is often a wish list of qualifications and skills. So if these do not match 100% with what you have, don’t be discouraged. Apply if you meet their base qualifications, that is, all of the required qualifications. But focus in the cover letter and the resume on showing that you do have relevant experience and skills and how they will allow you to quickly learn the rest of needed skills, that is, some of the desired but not required qualifications.
If you are unsure, step back and try to think in the shoes of a hiring manager. If you were a hiring manager, what would be the absolutely necessary qualifications and skills for the position? What would they consider as great strengths? What would they consider as something that they can easily teach you or something that they need you as an expert for? What would be a reason for the hiring manager to prefer you to more experienced candidates? Try to answer these things from the employer’s point of view while being honest and realistic about yourself. If you are called for an interview, be sure to ask about these things. The interviewers will be more than happy to tell you about the position you are applying for.
Also important is your interest and eagerness to pick up new skills and apply them to work. This is really important to employers. They know that skills can be learned but passion and enthusiasm are harder to find. So make sure that this comes out during the interview process.
5. If I am being called for a phone or in-person interview, the search committee and the hiring manager would be already familiar with everything I wrote in the cover letter and resume for sure. No.
The search committee members do their best to prepare for interviews, but they deal with a large volume of cover letters and resumes. They interview multiple candidates and can be serving on multiple search committees at the same time. Scheduling interviews itself can take up to 2-3 weeks at a large organization. So even if you were selected for an interview, your interviewers may well have to be reminded of why they picked you in the first place and what makes you a great candidate for the position.
Never assume that your interviewers would remember everything you wrote in your application. Do not repeat everything you put down in your cover letter or resume. But make sure to present the most important part of it in your interview more succinctly and convincingly. The search committee knows that they have already liked what they saw in your cover letter and resume. But it is up to you to make them remember and be assured of that in person (or over the phone).
6. Those who interview me will be looking for my weaknesses or flaws. Not at all.
When one is interviewing for a job, the whole interview process can seem intimidating. But believe it or not, the search committee and the hiring manager are the ones who want to see you successful most. They will ask questions, hoping and praying that you would give good or correct answers, and they really want your presentation to be excellent.
Why? It is because they already picked you once, twice, or three times out of a huge pile of resumes and cover letters. Just as you have worked on your cover letter and resume for hours, your search committee worked for hours to find out qualified candidates for the position. (And you would think that there would be plenty of qualified candidates in a tough job market. Surprisingly, this is not the case, more often than not. It is really really hard to find good candidates for many positions. So if you are one of them, they are more than happy to see you!) Remember this, and you will find a whole job search and interview process less daunting, intimidating, and stressful.
Last thought
Mostly what I really wanted to address is how to eliminate some of the anxiety and stress that are bound to go along with many new LIS graduates’ job search process. This is best dealt with by realizing that (a) some of the worries may be groundless, can be handled productively, or simply beyond control and that (b) job search and hiring are two sides of one coin and share one and the same goal: a fit between a person and an organization. No doubt finding this fit can take a while because the ‘fit’ is more than just a sum of work experiences or the list of skills. But with patience and smart strategies, you can make the process as less stressful as possible. Please share any tips you can offer in the comments!
I am closing this post with some really excellent tips from the librarian who has a great deal of experience in hiring librarians (much much more than I have) and was generous enough to share them with me for all of you.
Never hide who you are or what’s happened in your career.
Don’t avoid dates on resumes and make a resume a clear and simple progression of what you’ve done.
And being clear about your jobs and education is infinitely more important that some bland statement of objectives.
Do not repeat what is on the resume in the cover letter.
Look for an eloquent and simple way of expressing who you are.
Demonstrate your ability and confidence; don’t just state that you are capable
Librarians’ strong interest in programming is not surprising considering that programming skills are crucial and often essential to making today’s library systems and services more user-friendly and efficient for use. Not only for system-customization, computer-programming skills can also make it possible to create and provide a completely new type of service that didn’t exist before. However, programming skills are not part of most LIS curricula, and librarians often experience difficulty in picking up programming skills.
In this post, I would like to share some effective strategies to obtain coding skills and cover common mistakes and obstacles that librarians make and encounter while trying to learn how to code in the library environment based upon the presentation that I gave at Charleston Conference last month, “Geek out: Adding Coding Skills to Your Professional Repertoire.†(slides: http://www.slideshare.net/bohyunkim/geek-out-adding-coding-skills-to-your-professional-repertoire). At the end of this post, you will also find a selection of learning and community resources.
How To Obtain Coding Skills, Effectively
1. Pick a language and concentrate on it.
There are a huge number of resources available on the Web for those who want to learn how to program. Often librarians start with some knowledge in markup languages such as HTML and CSS. These markup languages determine how a block of text are marked up and presented on the computer screen. On the other hand, programming languages involve programming logic and functions. An understanding of the basic programming concepts and logic can be obtained by learning any programming language. There are many options, and some popular choices are JavaScript, PHP, Python, Ruby, Perl, etc. But there are many more. Â For example, if you are interested in automating tasks in Microsoft applications such as Excel, you may want to work with Visual Basic. If you are unsure about which language to pick, search for a few online tutorials for a few languages to see what their different syntaxes and examples are like. Even if you do not understand the content completely, this will help you to pick the language to learn first.
2. Write and run the code.
Once you choose a language to learn, there are many paths that you can follow. Taking classes at a local community college or through an online school may speed up the initial process of learning, but it could be time-consuming and costly. Following online tutorials and trying each example is a good alternative that many people take. You may also pick up a few books along the way to supplement the tutorials and use them for reference purposes.
If you decide on self-study, make sure that you actually write and run the code in the examples as you follow along the books and the tutorials. Most of the examples will appear simple and straightforward. But there is a big difference between reading through a code example and being actually able to write the code on your own and to run it successfully. If you read through programming tutorials and books without actually doing the hands-on examples on your own, you won’t get much benefit out of your investment. Programming is a hands-on skill as much as an intellectual understanding.
3. Continue to think about how coding can be applied to your library.
Also important is to continue to think about how your knowledge can be applied to your library systems and environment, which is often the source of the initial motivation for many librarians who decide to learn how to program. The best way to learn how to program is to program, and the more you program the better you will become at programming. So at every chance of building something with the new programming language that you are learning, no matter how small it is, build it and test out the code to see if it works the way you intended.
4. Get used to debugging.
While many who struggle with learning how to code cite lack of time as a reason, the real cause is likely to be failing to keep up the initial interest and persist in what you decided to learn. Learning how to code can be exciting, but it can also be a huge time-sink and the biggest source of frustration from time to time. Since the computer code is written for a machine to read, not for a human being, one typo or a missing semicolon can make the program non-functional. Finding out and correcting this type of error can be time-consuming and demoralizing. But learning how to debug is half of programming. So don’t be discouraged.
5. Find a community for social learning and support.
Having someone to talk to about coding problems while you are learning can be a great help. Sign up for listservs where coding librarians or library coders frequent, such as code4lib and web4lib to get feedback when you need. Research the cause of the problem that you encounter as much as possible on your own. When you still are unsure about how to go about tackling it, post your question to the sites such as Stack Overflow for suggestions and answers from more experienced programmers. It is also a good idea to organize a study group with like-minded people and get support for both coding-related and learning-related problems. You may also find local meet-ups available in your area using sites like MeetUp.com.
Don’t be intimidated by those who seem to know much more than you in those groups (as you know much more about libraries than they do and you have things to contribute as well), but be aware of the cultural differences between the developer community and the librarian community. Unlike the librarian community that is highly accommodating for new librarians and sometimes not-well-thought-out questions, the developer community that you get to interact with may appear much less accommodating, less friendly, and less patient. However, remember that reading many lines of code, understanding what they are supposed to do, and helping someone to solve a problem occurring in those lines can be time-consuming and difficult even to a professional programmer. So it is polite to do a thorough research on the Web and with some reference resources first before asking for others’ help. Also, always post back a working solution when your problem is solved and make sure to say thank you to people who helped you. This way, you are contributing back to the community.
6. Start working on a real-life problem ‘now.’ Don’t wait!
Librarians are often motivated to learn how to code in order to solve real-life problems they encounter at their workplace. Solving a real-life problem with programming is therefore the most effective way to learn and to keep up the interest in programming. One of the greatest mistake in learning programming is putting off writing one’s own code and waiting to work on a real-life problem for the reason that one doesn’t know yet enough to do so. While it is easy to think that once you learn a bit more, it would be easier to approach a problem, this is actually a counter-productive learning strategy as far as programming is concerned because often the only way to find out what to learn is by trying to solve a problem.
7. Build on what you learned.
Another mistake to avoid in learning how to program is failing to build on what one has learned. Having solved one set of problem doesn’t mean that you will remember that programming solution you created next time when you have to solve a similar problem. Repeating what one has succeeded at and expanding on that knowledge will lead to a stronger foundation for more advanced programming knowledge. Also instead of trying to learn more than one programming language (e.g. Python, PHP, Ruby, etc.) and/or a web framework (e.g. Django, cakePHP, Ruby On Rails, etc.) at the same time, first try to become reasonably good at one. This will make it much easier to pick up another language later in the future.
8. Code regularly and be persistent.
It is important to understand that learning how to program and becoming good at it will take time. Regular coding practice is the only way to get there. Solving a problem is a good way to learn, but doing so on a regular basis as often as possible is the best way to make what you learned stick and stay in your head.
While is it easy to say practice coding regularly and try to apply it as much as possible to the library environment, actually doing so is quite difficult. There are not many well-established communities for fledgling coders in libraries that provide needed guidance and support. And while you may want to work with library systems at your workplace right away, your lack of experience may prove problematic in gaining a necessary permission to tinker with them. Also as a full-time librarian, programming is likely to be thrown to the bottom of your to-do list.
Be aware of these obstacles and try to find a way to overcome them as you go. Set small goals and use them as milestones. Be persistent and don’t be discouraged by poor documentation, syntax errors, and failures. With consistent practice and continuous learning, programming can surely be learned.
*** This post has been also published on ACRL TechConnect on Nov. 20, 2012. ***
Librarians often use presentation slides to teach a class, run a workshop, or give a talk. Ideally you should be able to access the Internet easily at those places. But more often than not, you may find only spotty Internet signals. If you had planned on using your presentation slides stored in the cloud, no access to the Internet would mean no slides for your presentation. But it doesn’t have to be that way. In this post, we will show you how to locally save your presentation slides on your iPad, so that you will be fully prepared to present without Internet access. You will only need a few tools, and the best of all, those tools are all freely available.
1. Haiku Deck – Make slides on the iPad
If your presentation slides do not require a lot of text, Haiku Deck is a nice iPad app for creating a complete set of slides without a computer. The Haiku Deck app allows you to create colorful presentation slides quickly by searching and browsing a number of CC-licensed images and photographs in Flickr and to add a few words to each slide. Once you select the images, Haiku Deck does the rest of work, inserting the references to each Flickr image you chose and creating a nice set of presentation slides.
You can play and present these slides directly from your iPad. Since Haiku Deck stores these slides locally, you need access to the Internet only while you are creating the slides using the images in Flickr through Haiku Deck. For presenting already-made slides, you do not need to be connected to the Internet. If you would like, you can also export the result as a PowerPoint file from Haiku Deck. This is useful if you want to make further changes to the slides using other software on your computer. But bear in mind that once exported as a PowerPoint file, the texts you placed using Haiku Deck are no longer editable. Below is an example that shows you how the slides made with Haiku Deck look like.
Note. Click the image itself in order to see the bigger version.
So next time when you get a last-minute instruction request from a teaching faculty member, consider spending 10-15 minutes to create a colorful and eye-catching set of slides with minimal text to have it accompany your classroom instruction or a short presentation all on your iPad.
2. SlideShark – Display slides on the iPad
SlideShark is a tool not so much for creating slides as for displaying the slides properly on the iPad (and also for the iPhone). In order to use SlideShark, you need to install the SlideShark app on your iPad first and then create an account. Once this is done, you can go to the SlideShark website (https://www.slideshark.com/) and log in. Here you can upload your presentation files in the MS PowerPoint format.
Once the file is uploaded to the SlideShark website, open the SlideShark app on your iPad and sync your app with the website by pressing the sync icon on top. This will display all the presentation files that have been uploaded to your SlideShark website account. Here, you can download and save a local copy of your presentation on your iPad. You will need the live Internet connection for this task. But once your presentation file is downloaded onto your SlideShark iPad app, you no longer need to be online in order to display and project those slides. While you are using your iPad to display your slides, you can also place your finger on the iPad screen which will be displayed on the projector as a laser pointer mark.
Last but not least, when you pack your iPad and run to your classroom or presentation room, don’t forget to take your adapter. In order to connect your iPad to a projector, you usually need a iPad-VGA adapter because most projectors have a VGA port. But different adapters are used for different ports on display devices. So find out in advance if the projector you will be using has a VGA, DVI, or a HDMI port. (Also remember that if you have an adapter that connects your Macbook with a projector, that adapter will not work for your iPad. That is a mini DVI-VGA adapter and won’t work with your iPad.)
4. Non-free option: Keynote
Haiku Deck and SlideShark are both free. But if you are willing to invest about ten dollars for convenience, another great presentation app is Keynote (currently $9.99 in Apple Store). While Haiku Deck is most useful for creating simple slides with a little bit of text, Keynote allows you to create more complicated slides on your iPad. If you use Keynote, you also don’t have to go through SlideShark for the off-line display of your presentation slides.
Creating presentations on the Keynote iPad app is simple and uses the same conventions and user-interface as the familiar Keynote application for OS X. Both versions of Keynote can share the same presentation files, although care should be taken to use 1024 x 768 screen resolution and standard Apple fonts and slide templates. iCloud may be used to sync presentations between iPads and other computers and users can download presentations to the iPad and present without Internet access.
The iPad version of Keynote has many features that make Keynote loved by its users. You can add media, tables, charts, and shapes into your presentation. Using Keynote, you can also display your slides to the audience on the attached projector while you view the same slides with a timer and notes on your iPad. (See the screenshots below.) For those with an iPhone or iPod Touch, the Keynote Remote app allows presenters to remotely control their slideshows without the need to stand at the podium or physically touch the iPad to advance their slides.
Do you have any useful tips for creating slides and presenting with an iPad? Share your ideas in the comments!
*** This post has been also published on ACRLog on Oct. 29, 2012. ***
Today’s library users do not carry pencils and notebooks to a library. They do no longer want to be isolated to concentrate on deep study or contemplative reading when they are at a library. Rather, they have the dire need to be connected to the biggest library the human race ever had, the World Wide Web, always and even more so when they are at a library walking through the forest of fascinating knowledge and information. The traditional library space packed with stacks and carrels does not serve today’s library users well whether they are scholars, students, or the public visiting a library for research, study, or leisure reading. As more and more library resources are moved to the fast and convenient realm of the World Wide Web, libraries have been focusing on re-defining the library space. Now, many libraries boast attractive space almost comparable to trendy, comfortable, and vibrant coffee shops. The goal of these new library spaces are fostering communication, the exchange of ideas, and social learning.
How the loss of book stacks and carrels affects library patrons
However, some library patrons complain about this new and hip research and reading environment that libraries are creating. They do not experience comfort and excitement, which today’s libraries strive to provide in their new coffee-shop-or-makerspace-like library space. These patrons rather miss the old dusty moldy stacks packed with books, many of which were left untouched except by a handful of people for a very long time. They miss the quiet and secluded carrels often placed right outside of the stacks. They say that browsing a library’s physical collection in those stacks led them to many serendipitous discoveries and that in those tiny uncomfortable carrels, they were completely absorbed into their own thoughts reading away a pile of books and journals undisturbed by the worldly hustle and bustle.
This is an all-too-familiar story. The fast and convenient e-resources in library websites and the digital library collections seem to deprive us of something significant and important, that is, the secluded and sacred space for thought and contemplation and the experience of serendipitous discovery from browsing physical library collections. However, how much of this is our romantic illusion and how much of it is it a real fact?
How much of this environment made our research more productive in reality?
What we really love about browsing book stacks at a library
In the closing keynote of 2012 ACCESS Conference last Sunday, Bess Sadler, the application development manager at Standford University Libraries noted the phenomenon that library patrons often describe the experience of using the physical library collection in emotional terms such as ‘joyous,’ ‘immersive,’ and ‘beautiful’ characteristic to our right brain whereas they use non-emotional terms such as ‘fast’ and ‘efficient’ to describe their use of a library’s online/digital resources. The open question that she posed in her keynote was how to bring back those emotional responses associated with a library’s physical collection to a library’s digital collection and its interface. Those terms such as ‘joyous,’ ‘immersive,’ and ‘beautiful’ are often associated in a library user’s mind with their experience of serendipitous discovery which took place while they were browsing a library’s physical book stacks. Sadler further linked the concept of serendipitous discovery with the concept of ‘flow’ by Csikszentmihalyi and asked the audience how libraries can create such state of flow with their digital collections by improving their interfaces.
One of the slides from Bess Sadler’s Closing Keynote
The most annoying thing about the e-resources that today’s libraries offer is that the systems where these resources reside do not smoothly fit into anyone’s research workflow. How can you get into a zone when the database you are in keeps popping up a message asking if you want to renew the session or demands two or three different authentications for access? How can you feel the sense of smooth flow of thought in your head when you have to navigate from one system to another with puzzling and unwieldy interfaces in order to achieve simple tasks such as importing a few references or finding the full-text of the citation you found in an e-book or an online journal you were reading?
Today’s research environment that libraries offers with its electronic resources is riddled with so many irritating usability failures (often represented by too many options none of whose functions are clear) that we can almost safely say that it is designed anything but for the ‘flow’ experience. The fact that these resources’ interfaces are designed by library system vendors and light years outdated compared to the interfaces available for individual consumers and that librarians have little or no control over them only exacerbate the problem. So I always associated the concept of flow with usability in the library context. And considering how un-user-friendly the research environment offered by today’s libraries is overall, asking for ‘joyous,’ ‘immersive,’ or ‘beautiful’ appeared to me to be a pretty tall order.
But more importantly, the obstacles to the ‘flow’ experience are not unique to online resources or digital libraries. Similar problems do exist in the physical collections as well. When I was a grad student, the largest library collection in North America was available to me. But I hated lugging back and forth a dozen periodicals and monographs between my apartment and the university just to get them renewed. (This was the time before the online renewal!) After the delightful moment of finding out in the online catalog that those rare scholarly books that I want are indeed available somewhere in that large library system at Harvard, I grumbled at the prospect of either navigating the claustrophobic rows and rows of stacks at Widener Library in order to locate those precious copies or running to a different library on campus that is at least a half mile away. At those times, the pleasure of browsing the dusty stacks or the joy of a potential serendipitous discovery was the last thing that I cared for. I was very much into my research and exactly for that reason, if I could, I would have gladly selected the delivery option of those books that I wanted to save time and get into my research flow as soon as possible. And I did so as soon as my university library started moving many books to an off-site storage and delivering them on-demand next day at a circulation desk. I know that many faculty at academic institutions strongly protest against moving a library’s physical collection to an off-site storage. But I confess that many times when the library catalog showed the book I wanted as located on the stacks and not at the off-site storage, I groaned instead of being delighted. I won’t even discuss what it was like to me to study in a library carrel. As an idea, it is a beautiful one to be immersed in research readings in a carrel; in reality, the chair is too hard, the space is too dark and claustrophobic, the air is stale, and the coffee supply is, well, banned near the stacks where those carrels are. Enough said.
The point I am trying to make is that we often romanticize our interaction with the physical stacks in a library. The fact that we all love the library stacks and carrels doesn’t necessarily mean that we love them for the reasons we cite. More often than not, what we really like and miss about the library stacks and carrels is not their actual practical utility to our research process but the ambiance.Strand, the used bookstore in NYC is famous for its 18 miles of books. Would you walk along the 18 miles of books even if you know in advance that you are not going to make any serendipitous discovery nor find nothing directly useful for your research topic at hand? Yes you bet. Would you walk by the stacks in Trinity College Library in Dublin, UK even though you are not doing anything related to research? A very few of us would say ‘No’ to such an invitation.
Can you resist walking between these stacks? Our desire doesn’t always correspond to its practical utility.
The library book stacks as high as the walls filling up the whole floor generate the sense of awe and adventure in us because it gives us the experience of ‘physically’ surrounded by knowledge. It is magical and magnificent. It is amazing and beautiful. This is where all those emotional adjectives originate. In the library stacks, we get to ‘see’ the knowledge that is much bigger than us, taller than us, and wider than us. (Think of ‘the sublime’ in Kantian aesthetics.) When our sensory organs are engaged this way, we do not experience the boredom and tediousness that we usually feel when we scroll up and down a very long list of databases and journals on a library web page. We pause, we admire, and we look up and down. We are engrossed by the physicality of the stacks and the books on them. And suddenly all our attention is present and focused on that physicality. So much so that we even forget that we were there to find a certain book or to work on a certain research topic. It is often at these moments that we serendipitously stumble upon something relevant to what we were looking for but have forgotten to do so. Between the magnificent tall stacks filled with books, you are distracted from your original mission (of locating a particular book) but are immersed in this new setting at the same time. The silence, the high ceiling, the Gothic architectural style of an old library building, and the stacks that seems to go on forever in front of us. These are all elements that can be conducive to a serendipitous discovery but “if and only if” we allow ourselves to be influenced by them. On the other hand, if you are zooming in on a specific book, all of this visual magnificence could be a nuisance and a bother. To a scholar who can’t wait to read all of the readings after physically collecting them first, the collection process is a chore at best. To this person, neither a serendipitous discovery nor the state of ‘flow’ would be no doubt more difficult to happen in between the stacks.
If this is a relatively accurate description of a serendipitous discovery that we experience while browsing the physical collection on library book-stacks, what we really miss about the traditional library space may well be the physicality of its collection, the physical embodiment of the abstract concept of knowledge and information in abundance, and its effect on our mental state, which renders our mind more susceptible to a serendipitous discovery. And what we are most unhappy about the digital form of knowledge and information offered by today’s libraries could be that it is not presented in the space and environment where we can easily tune our mind into the content of such digital knowledge and information. It is the same Classical Greek text that you see when you pull out an old copy of Plato’s Meno in the narrow passage between tall book-stacks at Widener and when you pull up the text on your computer screen from the Perseus Digital Library. It is our state of mind influenced by the surroundings and environment that is different. That state of mind that we miss is not entirely dictated but heavily influenced by the environment we are present. We become different people at different places, as Alain de Botton says in his book, The Architecture of Happiness (Ch 1). Who can blame a library user when s/he finds it hard to transform a computer screen (which takes her to many digital collections and online resources from a library as well as all sorts of other places for entertainment and distraction) into the secluded and sacred space for thought and contemplation?
Using Perseus Digital Library is way more efficient for research and study the classical Greek texts than using the physical collection on your stacks. However, we still miss and need the experience of browsing the physical collection on the stacks.
How to facilitate the ‘flow’ and serendipity in today’s libraries
The fact that today’s libraries no longer control the physical surroundings of a library patron who is making use of their resources doesn’t mean that there are nothing libraries can do to make the research environment facilitate serendipitous discoveries and the state of ‘flow’ in a researcher’s mind, however. Today’s libraries offer many different systems for library users to access their online resources. As I have mentioned above, the interfaces of these systems can use some vast improvement in usability. When there are as few hindrances as possible for a library patron to get to what s/he is looking for either online or at the physical library space, s/he would be able to concentrate on absorbing the content more easily instead of being bogged down with procedures. The seamless interoperability between different systems would be very much desirable for researchers. So, improving the usability of library systems will take library patrons one step closer to obtaining the flow state in their research while using library resources online.
As far as the physical space of a library is concerned, libraries need to pay more attention to how the space and the environment of a library emotionally affects library patrons. Not all research and study is best performed by group-study or active discussion. Baylor University Libraries, for example, designate three different zones in their space: Silent, Quiet, and Active. While libraries transform more of their traditional stack-and-carrel space into vibrant group study rooms and conversation-welcoming open spaces, they also need to preserve the sense of the physical environment and surroundings for library patrons, because after all, all of us desire the feeling of being in a sacred and dedicated space for contemplation and deep thoughts from time to time. Such space is becoming rarer and rarer nowadays. Where else would people look for such space if not a library, which the public often equate to a building that embodies the vast amount of knowledge and resources in the physical form.
Facilitating the serendipitous discovery in browsing a library collection in the digital environment is more tricky because of the limitation of the current display mechanisms for digital information. In emulating the experience of browsing books in the physical form on a computer screen, the Google WebGL Bookcase has made some progress. But it would be much more efficient combined with a large display mechanism that allows a user to control and manipulate information and resources with gestures and bodily movements, perhaps something similar to what we have seen in the movie, Minority Report. However, note that information does not have to be bound in the form of books in the digital environment and that digital books do not have to be represented as a book with pages to thumb through and the spine where its title is shown . If we set aside the psychological factors that contribute to the occurrence of a serendipitous discovery, what is essential to efficient browsing boils down to how easily (i) we can scan through many different books (or information units such as a report or an article) quickly and effectively and (ii) zoom in/out and switch between the macro level (subjects, data types, databases, journals, etc) and the micro level (individual books, articles, photographs, etc. and their content). If libraries can succeed in designing and offering such interfaces for digital information consumption and manipulation, the serendipitous discovery and the efficient browsing in the digital library environment can not only match but even exceed that in the physical library book-stacks.
*** This blog post has been originally published in ACRL TechConnect 0n October 9, 2012. ***
My previous post “The simpest AJAX: writing your own code (1)” discussed a few Javascript and JQuery examples that make the use of the Flickr API. In this post, I try out APIs from providers other than Flickr. The examples will look plain to you since I didn’t add any CSS to dress them up. But remember that the focus here is not in presentation but in getting the data out and re-displaying it on your own. Once you get comfortable with this process, you can start thinking about a creative and useful way in which you can present and mash up the same data. We will go through 5 examples I created with three different APIs. Before taking a look at the codes, check out the results below first.
The first example is Pinboard. Many libraries moved their bookmarks in Del.icio.us to a different site when there was a rumor that Del.cio.us may be shut down by Yahoo. One of those sites were Pinboard. By getting your bookmark feeds from Pinboard and manipulating them, you can easily present a subset of your bookmark as part of your website.
(a) Display bookmarks in Pinboard using its API
The following page uses JQuery to access the JSONP feed of my public bookmarks in Pinboard. $.ajax() method is invoked on line 13. Line 15, jsonp:”cb”, gives the name to a callback function that will wrap the JSON feed data in it. Note line 18 where I print out data received into the console. This way, you can check if you are receiving JSONP feed in the console of Firebug. Line 19-22 uses $.each() function to access each element in the JSONP feed and the .append() method to add each bookmark’s title and url to the “pinboard” div. JQuery documentation has detailed explanation and examples for its functions and methods. So make sure to check it out if you have any questions about a JQuery function or method.
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<title>Pinboard: JSONP-AJAX Example</title>
<script type="text/javascript" src="http://jqueryjs.googlecode.com/files/jquery-1.3.2.min.js"></script>
</head>
<body>
<p> This page takes the JSON feed from <a href="http://pinboard.in/u:bohyunkim/">my public links in Pinboard</a> and re-presents them here. See <a href="http://feeds.pinboard.in/json/u:bohyunkim/">the Pinboard's JSON feed of my links</a>.</p>
<div id="pinboard"><h1>All my links in Pinboard</h1></div>
<script>
$(document).ready(function(){
$.ajax({
url:'http://feeds.pinboard.in/json/u:bohyunkim',
jsonp:"cb",
dataType:'jsonp',
success: function(data) {
console.log(data); //dumps the data to the console to check if the callback is made successfully
$.each(data, function(index, item){
$('#pinboard').append('<div><a href="' + item.u + '">' + item.d
+ '</a></div>');
}); //each
} //success
}); //ajax
});//ready
</script>
</body>
</html>
Here is the screenshot of the page. I opened up the Console window of the Firebug (since I dumped the received in line 18) and you can see the incoming data here. (Note. Click the images to see the large version.)
But it is much more convenient to see the organization and hierarchy of the JSONP feed in the Net panel of Firebug.
And each element of the JSONP feed can be drilled down for further details by clicking the object in each row.
(b) Display only a certain number of bookmarks
Now, let’s display only five bookmarks. In order to do this, only one more line is needed. Line 9 checks the position of each element and breaks the loop when the 5th element is processed.
Often libraries want to display bookmarks with a particular tag. Here I add a line using JQuery method $.inArray() to display only bookmarks tagged with ‘fiu.’ $.inArray()Â method takes value and array as parameters and returns 0 if the value is found in the array otherwise -1. Line 7 checks if the tag array of a bookmark (item.t) does include ‘fiu,’ and only in such case displays the bookmark. As a result, only the bookmarks with the tag ‘fiu’ are shown in the page.
$.ajax({
url:'http://feeds.pinboard.in/json/u:bohyunkim',
jsonp:"cb",
dataType:'jsonp',
success: function(data) {
$.each(data, function(index, item){
if ($.inArray("fiu", item.t)!==-1) // if the tag is 'fiu'
$('#pinboard').append('<div><a href="' + item.u + '">' + item.d
+ '</a></div>');
}); //each
} //success
}); //ajax
II. Reddit API
My second example uses Reddit API. Reddit is a site where people comment on news items of interest. Here I used $.getJSON() instead of $.ajax() in order to process the JSONP feed from the Science section of Reddit. In the case of Pinboard API, I could not find out a way to construct a link that includes a call back function in the url. Some of the parameters had to be specified such as jsonp:”cb”, dataType:’jsonp’. For this reason, I needed to use $.ajax() function. On the other hand, in Reddit, getting the JSONP feed url was straightforward: http://www.reddit.com/r/science/.json?jsonp=cb.
Line 19 adds a title of the page. Line 20-22 extracts the title and link to the news article that is being commented and displays it. Under the news item, the link to the comments for that article in Reddit is added as a bullet item. You can see that, in Line 17 and 18, I have used the console to check if I get the right data and targeting the element I want and then commented out later.
This is just an example, and for that reason, the result is a rather simplified version of the original Reddit page with less information. But as long as you are comfortable accessing and manipulating data at different levels of the JSONP feed sent from an API, you can slice and dice the data in a way that suits your purpose best. So in order to make a clever mash-up, not only the technical coding skills but also your creative ideas of what different sets of data and information to connect and present to offer something new that has not been available or apparent before.
My second example uses Reddit API. Reddit is a site where people comment on news items of interest. Here I used $.getJSON() method instead of $.ajax() in order to process the JSONP feed from the Science section of Reddit. In the case of Pinboard API, I could not find out a way to construct a link for a call back function. Some of the parameters had to be specified such as jsonp:”cb”, dataType:’jsonp’. So I needed to use $.ajax() method.
On the other hand, in Reddit, getting the JSONP feed url was straightforward: http://www.reddit.com/r/science/.json?jsonp=cb.  Line 19 adds a title of the page. Line 20-22 extracts the title and link to the news article that is being commented and displays it. Under the news item, the link to the comments for that article in Reddit is added as a bullet item.You can see that in Line 17 and 18, I have used the console to check if I get the right data and targeting the element I want.
This is just an example, and for that reason, the result is rather a simplified version of the original Reddit page with less information. But as long as you are comfortable accessing and manipulating data at different levels of the JSONP feed sent from an API, you can slice and dice the data in a way that suits your purpose best.
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<title>Reddit-Science: JSONP-AJAX Example</title>
<script type="text/javascript" src="http://ajax.googleapis.com/ajax/libs/jquery/1.8.0/jquery.min.js"></script>
</head>
<body>
<p> This page takes the JSONP feed from <a href="http://www.reddit.com/r/science/">Reddit's Science section</a> and presents the link to the original article and the comments in Reddit to the article as a pair. See <a href="http://www.reddit.com/r/science/.json?jsonp=?">JSONP feed</a> from Reddit.</p>
<div id="feed"> </div>
<script type="text/javascript">
//run function to parse json response, grab title, link, and media values, and then place in html tags
$(document).ready(function(){
$.getJSON('http://www.reddit.com/r/science/.json?jsonp=?', function(rd){
//console.log(rd);
//console.log(rd.data.children[0].data.title);
$('#feed').html('<h1>*Subredditum Scientiae*</h1>');
$.each(rd.data.children, function(k, v){
$('#feed').append('<div><p>'+(k+1)+': <a href="' + v.data.url + '">' + v.data.title+'</a></p><ul><li style="font-variant:small-caps;font-size:small"><a href="http://www.reddit.com'+v.data.permalink+'">Comments from Reddit</a></li></ul></div>');
}); //each
}); //getJSON
});//ready
</script>
</body>
</html>
The structure of a JSON feed can be confusing to make out particularly. So make sure to use the Firebug Net window to figure out the organization of the feed content and the property name for the value you want.
But what if the site from which you would like to get data doesn’t offer JSONP feed? Fortunately you can convert any RSS or XML feed into JSONP feed. Let’s take a look!
III. PubMed Feed with Yahoo Pipes API
Consider this PubMed search. This is simple search that looks for items in PubMed that has to do with Florida International University College of Medicine where I work. You may want to access the data feed of this search result, manipulate, and display in your library website. So far, we have performed a similar task with the Pinboard and the Reddit API using JQuery. But unfortunately PubMed does not offer any JSON feed. We only get RSS feed instead from PubMed.
This is OK, however. You can either manipulate the RSS feed directly or convert the RSS feed into JSON, which you are more familiar with now. Yahoo Pipes is a handy tool for just that purpose. You can do the following tasks with Yahoo Pipes:
combine many feeds into one, then sort, filter and translate it.
geocode your favorite feeds and browse the items on an interactive map.
power widgets/badges on your web site.
grab the output of any Pipes as RSS, JSON, KML, and other formats.
Furthermore, there may be a pipe that has been already created for exactly what you want to do by someone else. As PubMed is a popular resource, I found a pipe for PubMed search. I tested, copied the pipe, and changed the search term. Here is the screenshot of my Yahoo Pipe.
If you want to change the pipe, you can click “View Source” and make further changes. Here I just changed the search terms and saved the pipe.
Line 25 enables you to bring in this JSONP feed and invokes the callback function named “myCallback.” Line 14-23 defines this callback function to process the received feed. Line 18-20 takes the JSON data received at the level of data.value. item, and prints out each item’s title (item.title) with a link (item.link). Here I am giving a number for each item by (index+1). If you don’t put +1, the index will begin from 0 instead of 1. Line 21 stops the process when the processed item reaches 5 in number.
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<title>PubMed and Yahoo Pipes: JSONP-AJAX Example</title>
<script type="text/javascript" src="http://jqueryjs.googlecode.com/files/jquery-1.3.2.min.js"></script>
</head>
<body>
<p> This page takes the JSONP feed from <a href="http://pipes.yahoo.com/pipes/pipe.info?_id=e176c4da7ae8574bfa5c452f9bb0da92"> a Yahoo Pipe</a>, which creates JSONP feed out of a PubMed search results and re-presents them here.
<br/>See <a href="http://pipes.yahoo.com/pipes/pipe.run?_id=e176c4da7ae8574bfa5c452f9bb0da92&_render=json&limit=10&term=%22Florida+International+University%22+and+%22College+of+Medicine%22&_callback=myCallback">the Yahoo Pipe's JSON feed</a> and <a href="http://www.ncbi.nlm.nih.gov/pubmed?term=%22Florida%20International%20University%22%20and%20%22College%20of%20Medicine%22">the original search results in PubMed</a>.</p>
<div id="feed"></div>
<script type="text/javascript">
//run function to parse json response, grab title, link, and media values - place in html tags
function myCallback(data) {
//console.log(data);
//console.log(data.count);
$("#feed").html('<h1>The most recent 5 publications from <br/>Florida International University College of Medicine</h1><h2>Results from PubMed</h2>');
$.each(data.value.items, function(index, item){
$('#feed').append('<p>'+(index+1)+': <a href="' + item.link + '">' + item.title
+ '</a></p>');
if (index == 4) return false; //display the most recent five items
}); //each
} //function
</script>
<script type="text/javascript" src="http://pipes.yahoo.com/pipes/pipe.run?_id=e176c4da7ae8574bfa5c452f9bb0da92&_render=json&limit=10&term=%22Florida+International+University%22+and+%22College+of+Medicine%22&_callback=myCallback"></script>
</body>
</html>
Do you feel more comfortable now with APIs? With a little bit of JQuery and JSON, I was able to make a good use of third-party APIs. Next time, I will try the Worldcat Search API, which is closer to the library world and see how that works.

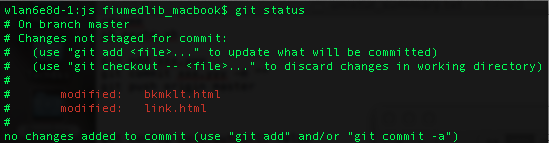
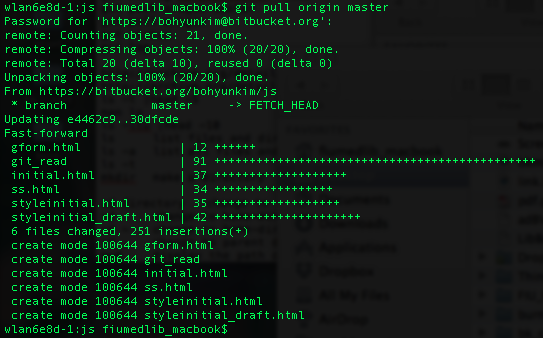
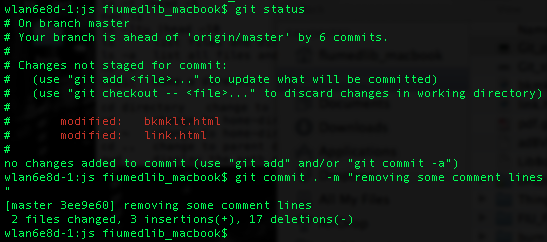
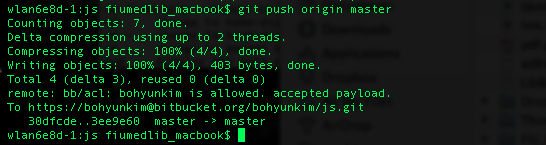
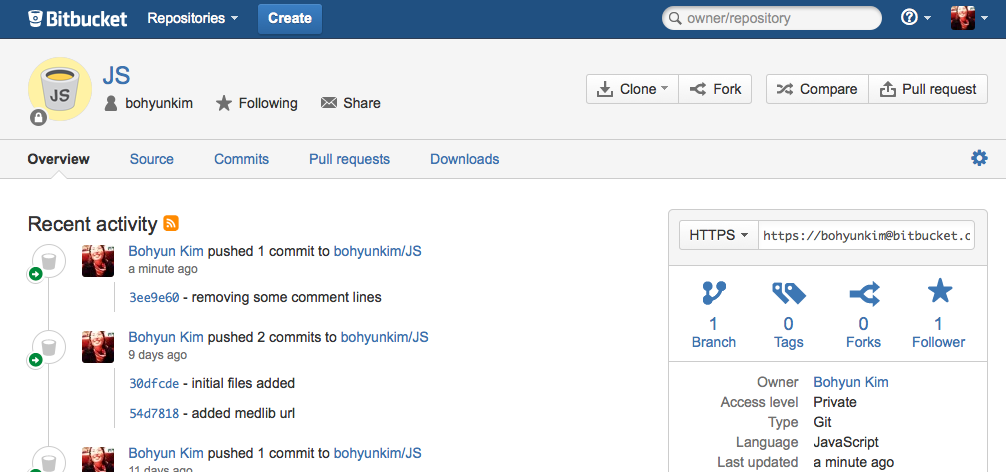
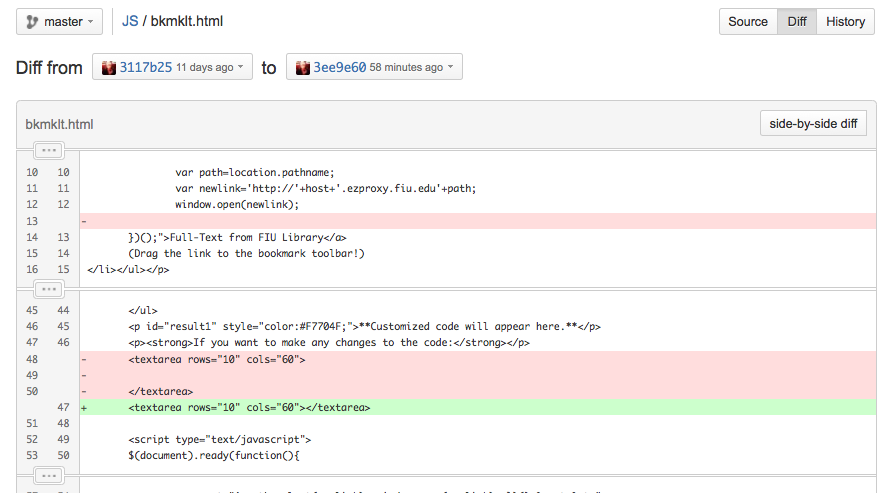
























{kind=link}